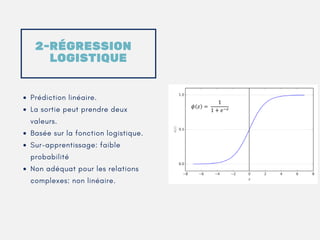
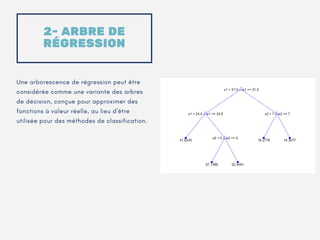
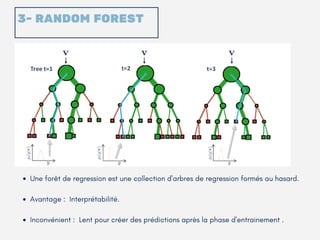
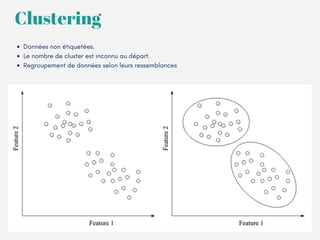
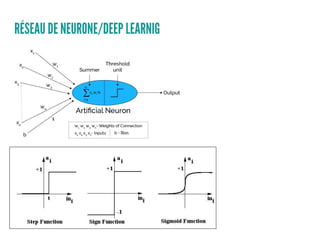
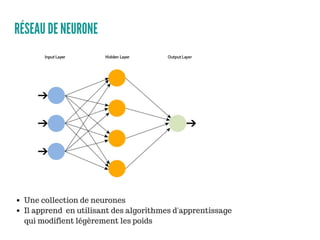
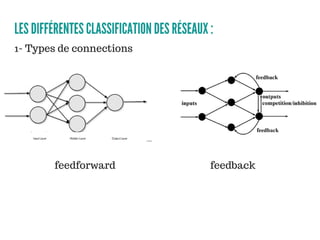
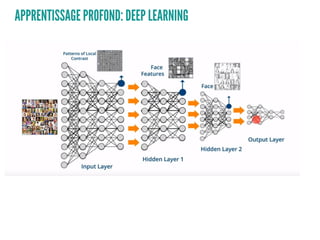
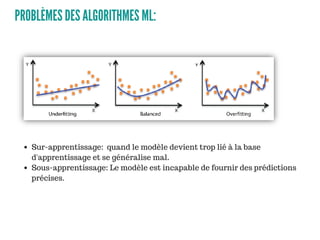
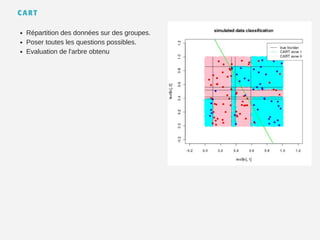
Le document présente un aperçu des algorithmes de machine learning et de deep learning, incluant des approches comme la régression linéaire, les arbres de décision et le clustering. Il discute des avantages et des inconvénients de chaque méthode, ainsi que des problèmes courants tels que le sur-apprentissage et le sous-apprentissage. En conclusion, il appelle à l'utilisation d'outils pour simplifier et automatiser ces tâches.