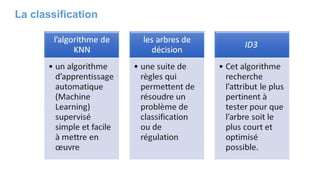
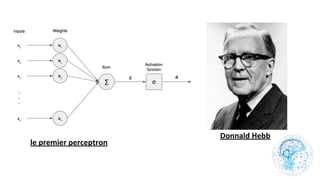
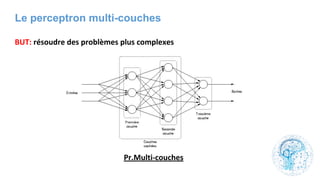
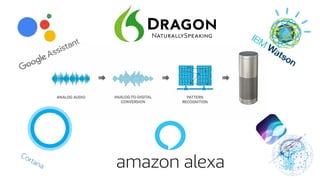
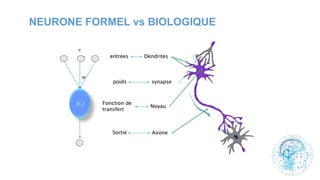
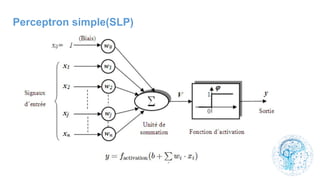
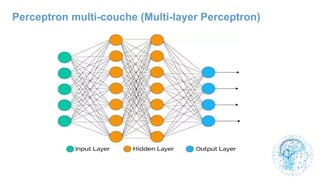
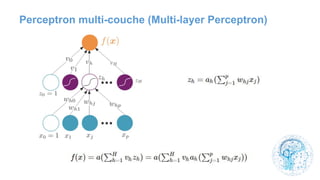
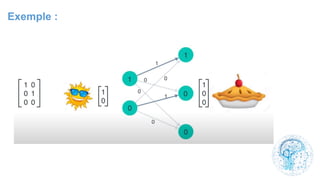
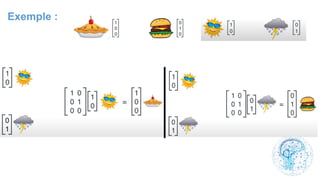
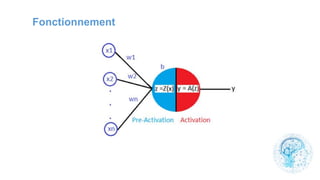
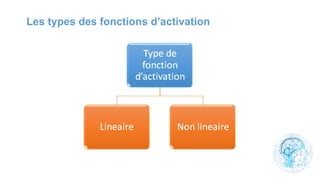
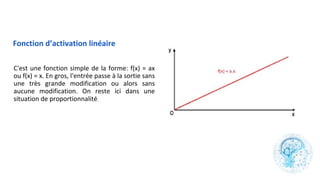
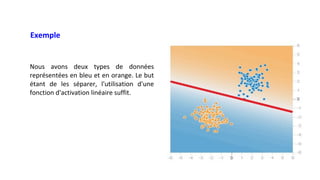
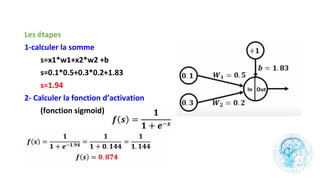
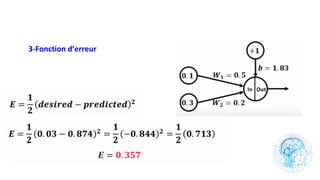
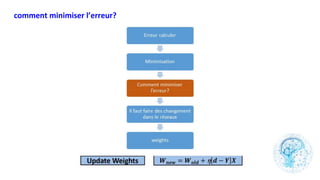
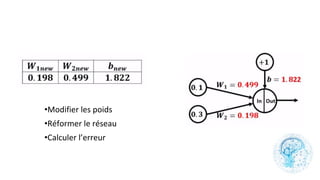
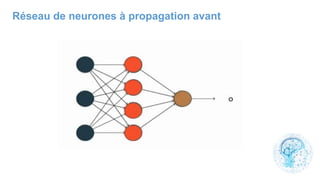
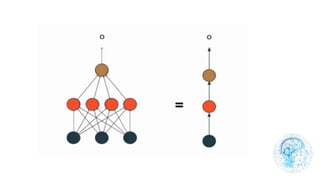
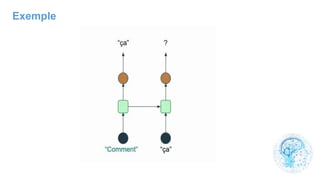
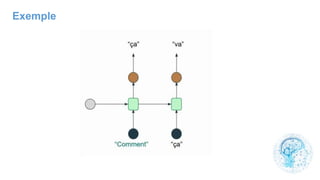
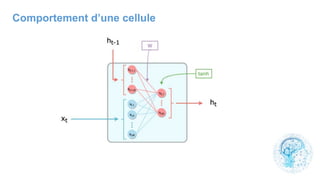
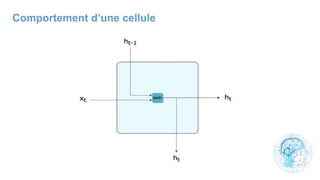
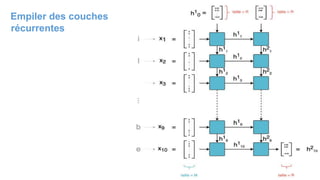
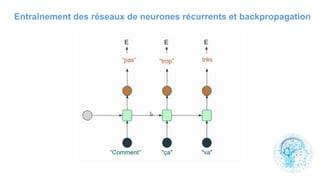
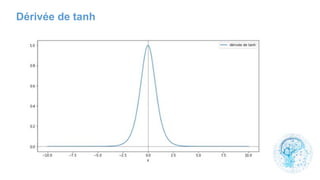
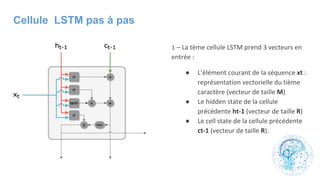
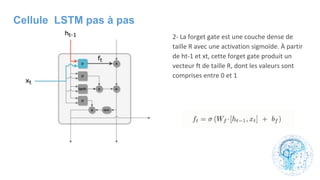
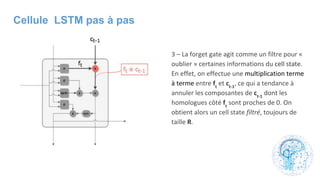
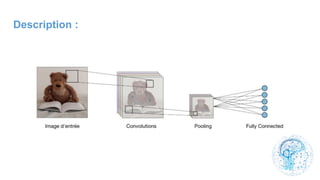
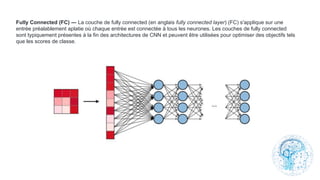
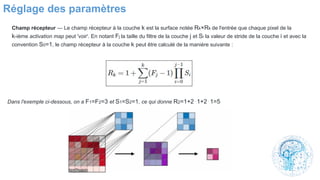
Le chapitre 6 traite des réseaux de neurones, notamment de leur historique, architecture, et types tels que le perceptron et les réseaux de neurones convolutifs. Il aborde également les fonctions d'activation, les applications des réseaux de neurones, et les limites de ces architectures dans divers domaines. Enfin, le chapitre décrit des méthodes d'entraînement et d'ajustement des paramètres des modèles de réseaux de neurones.
































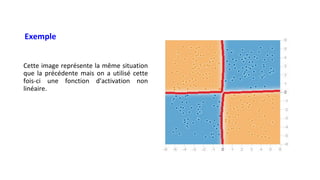

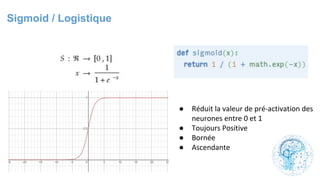

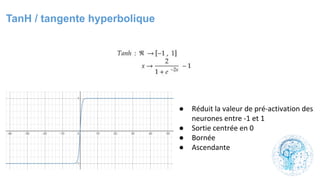

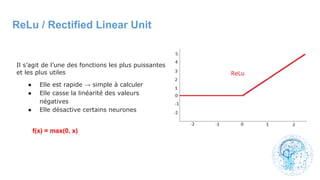

















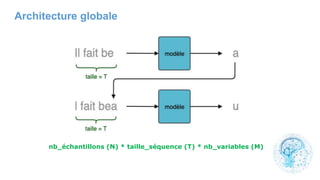
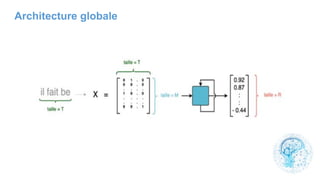
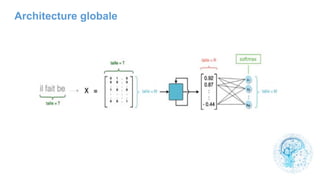
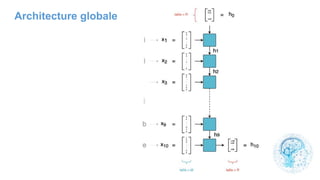











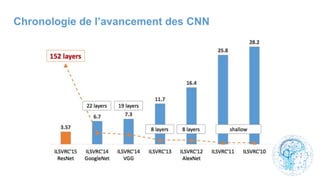
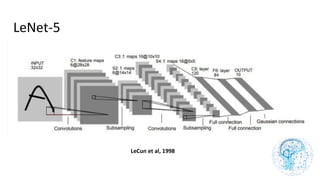
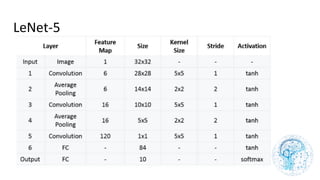

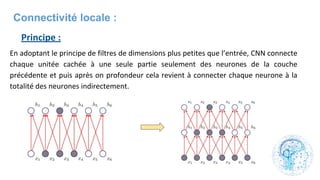































































![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)





