







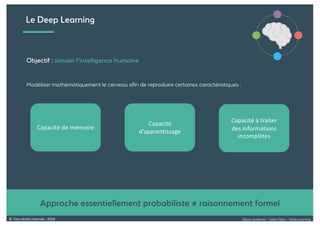

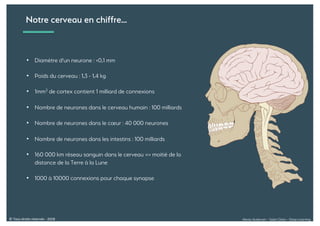
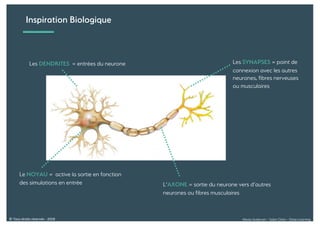
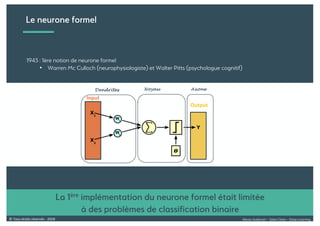

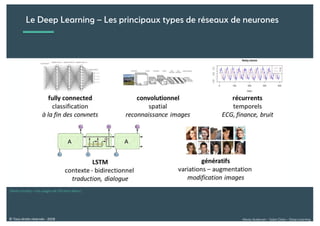


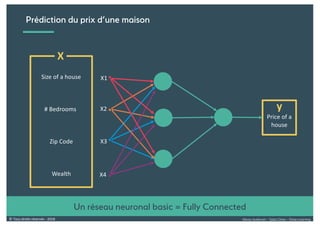
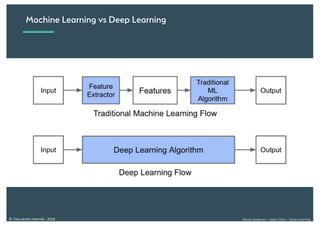
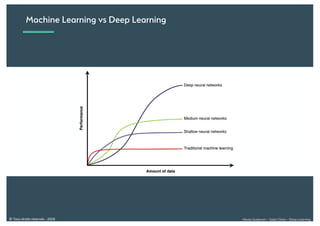

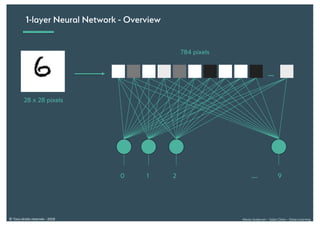
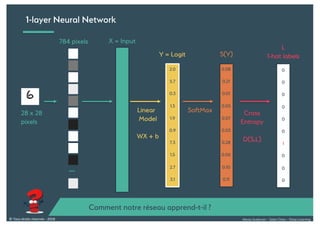

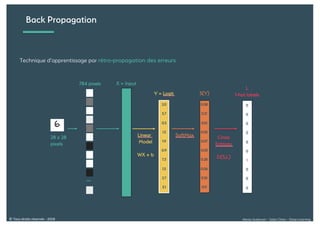
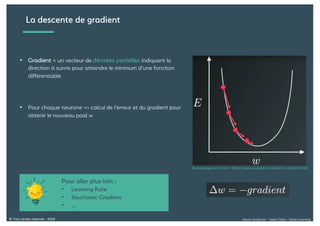
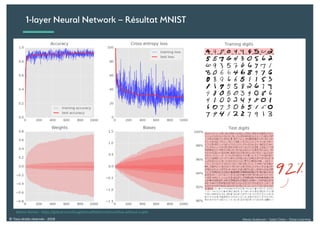
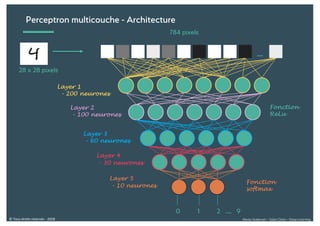
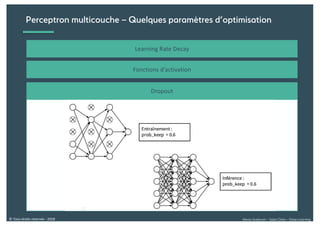
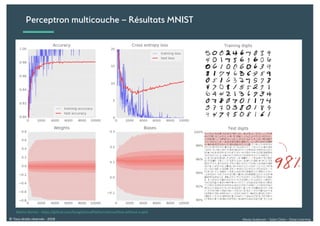

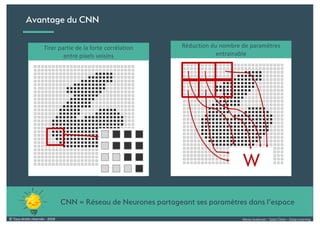

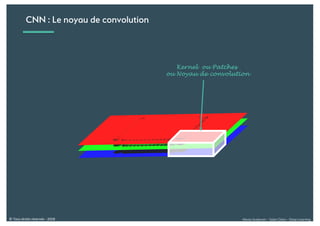
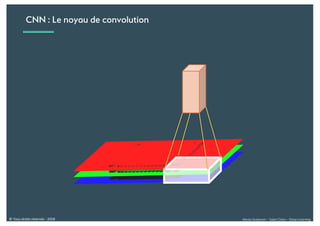
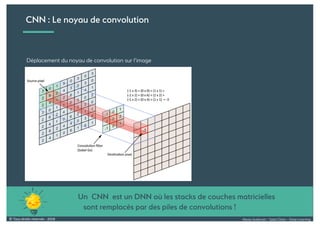
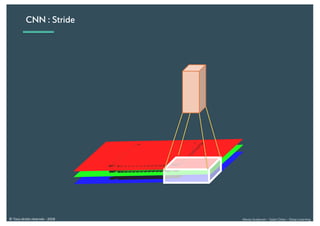
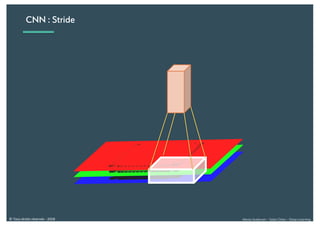
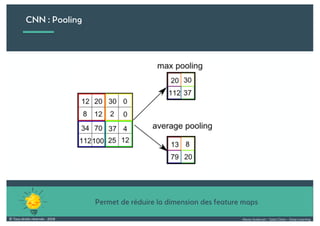
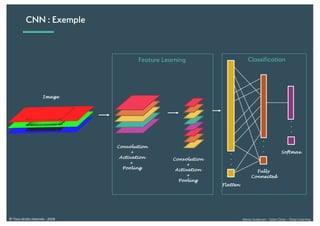
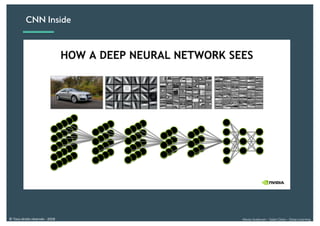
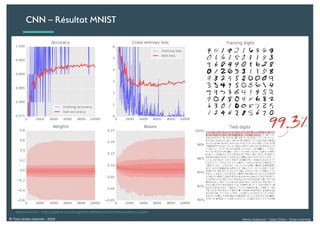

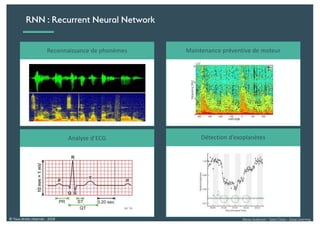
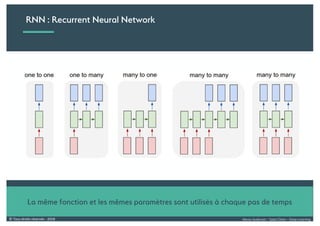
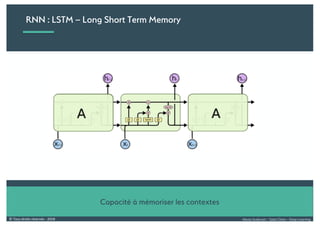



Le document présente une introduction au deep learning, en expliquant son évolution historique depuis les débuts de l'intelligence artificielle jusqu'à ses applications modernes. Il aborde des concepts tels que les neurones artificiels, les réseaux de neurones profonds, les CNN, RNN, et GAN, ainsi que des techniques d'apprentissage comme la rétro-propagation et la descente de gradient. Enfin, il mentionne certaines applications de ces technologies dans divers domaines.


















![Comprendre l’intelligence artificielle [webinaire]](https://cdn.slidesharecdn.com/ss_thumbnails/technologiawebinaireintelligenceartificielleclaudemarson01042019-190403213713-thumbnail.jpg?width=640&height=640&fit=bounds)




























