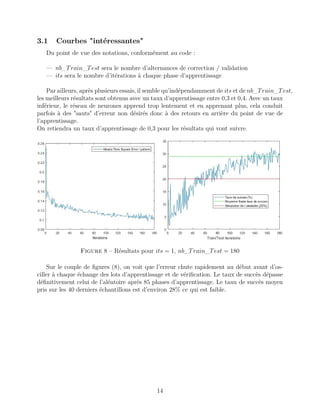
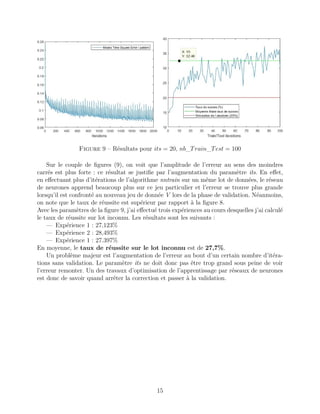
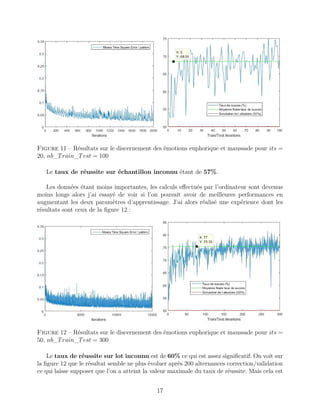
Ce rapport de projet explore l'apprentissage par réseaux de neurones dans le cadre de la reconnaissance vocale pour détecter les émotions humaines. Il décrit la méthodologie de traitement des données, l'architecture des réseaux de neurones et les résultats obtenus dans la classification des émotions, tout en réfléchissant aux implications de cette technologie. Le projet vise à permettre à un robot d'adapter son comportement en fonction de l'état émotionnel de l'utilisateur.









![Figure 4 – Tracé de la fonction sigmoïde sur l’intervalle [-10 ; 10]
1.2.2 Apprentissage
Nous avons présenté comment était modélisée, mathématiquement, la transmission d’un
message d’entrée à travers toutes les couches d’un réseau de neurones. Décrivons à présent
le processus qui permet au réseau de réellement apprendre.
La méthode consiste à envoyer en entrée les exemples que nous avons choisi et de fournir
la sortie que nous voudrions que le réseau renvoie. Dans l’exemple de la détection de sentier
sur une photo, il suffit de fournir une image de chemin et l’entier "1". Il existe alors des
algorithmes permettant de faire évoluer les poids au fil des exemples traités, de simuler le
comportement du réseau et de calculer l’erreur commise par le réseau, c’est à dire la différence
entre la sortie voulue et celle proposée par le réseau avec les poids actuels. La méthode de
la descente de gradient permet d’optimiser la convergence des poids vers ceux minimisant
l’erreur. C’est l’algorithme train qui fera ce travail dans notre étude.
A chaque itération de cet algorithme, l’erreur est calculée et elle décroit généralement
exponentiellement avant de remonter si on a réalisé un sur-entraînement, ce qui est contre-
productif. A la fin d’une phase d’apprentissage (dite de correction), il est judicieux de tester
le jeu de poids trouvé sur de nouveaux exemples pour en analyser les performances : c’est la
phase de validation. Ensuite, dans le but de ne pas perdre le potentiel d’apprentissage de ces
nouveaux échantillons, on permute les exemples ayant servi à la correction et à la validation
et on recommence une phase d’entraînement. Au bout d’un certain nombre d’alternances
correction/validation, on réalise un test final sur des exemples non encore traités par le
réseau et on calcule le taux de réussite. Ainsi, on obtient une valeur objective de la capacité
du réseau à traiter des cas qu’il n’a encore jamais rencontrés.
7](https://image.slidesharecdn.com/rapportia-190510130451/85/Rapport-projet-Master-2-Intelligence-Artificielle-9-320.jpg)

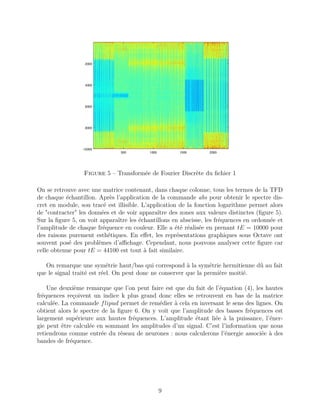
![Figure 6 – Transformée de Fourier Discrète traitée du fichier 1
2.2 Entrées du réseau de neurones
Combien de bandes de fréquences faut-il définir et quelles limites donner à chacune d’elle ?
Pour répondre à cette question, basons-nous sur la remarque que nous avons faite au sujet
de la figure 5 : le tracé est devenu lisible en appliquant la fonction logarithme qui "contracte"
les données en transformant les puissances en facteurs multiplicatifs. Ceci laisse supposer
que l’énergie contenue dans le signal diminue exponentiellement quand la fréquence associée
augmente. Nous choisirons donc de sommer les amplitudes du signal de la manière suivante :
— BF1 = [X(1), X(2)]
— BF2 = [X(3), X(4)]
— ...
— BFi = [X(2i−1
+ 1), X(2i
)]
— ...
jusqu’à ce que la taille d’un échantillon ne soit pas un multiple de 2n+2
. Ainsi la taille de la
bande de fréquence augmente exponentiellement pour compenser la décroissance exponen-
tielle d’énergie. Notons que dans notre cas, cela définit 14 classes.
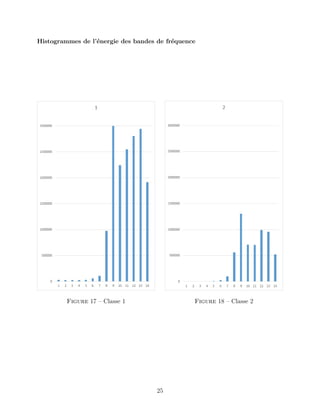
2.3 Pertinence du modèle
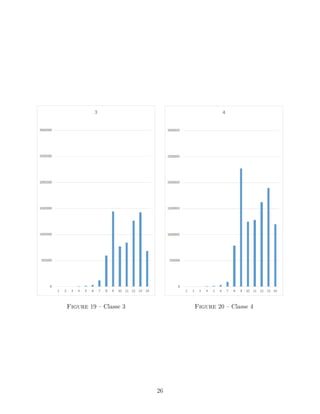
Un tel choix est-il pertinent ? En annexe, on trouvera cinq histogrammes sur lesquels on
a représenté l’énergie des bandes de fréquences ainsi définies pour les cinq classes d’émotion.
On a sommé l’énergie de tous les échantillons afin d’avoir un résultat unique pour chaque
classe. Attardons-nous sur l’énergie associée à la bande de fréquence la plus haute. Sur la
figure 7, on a tracé l’énergie associée à cette bande de fréquence. On peut voir qu’elle est
10](https://image.slidesharecdn.com/rapportia-190510130451/85/Rapport-projet-Master-2-Intelligence-Artificielle-12-320.jpg)


![De fait, L soit de la forme :
L =
E1,1 · · · E1,14 c1
...
...
...
Ei,1 · · · Ei,14 ci
...
...
...
En,1 · · · Ei,14 cn
où :
∀i ∈ [|1, n|], ci ∈ {0.1, 0.2, 0.3, 0.4, 0.5}
et :
n =
5
2
× nb_echant_min
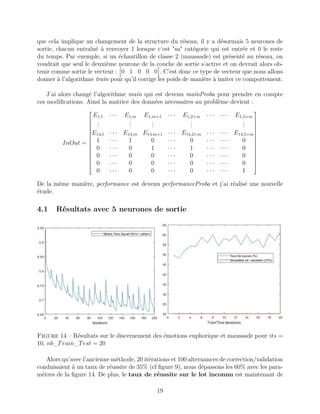
3 Résultats
Dans le but d’analyser les résultats produits par le réseau de neurones, je me suis basé
sur deux indicateurs :
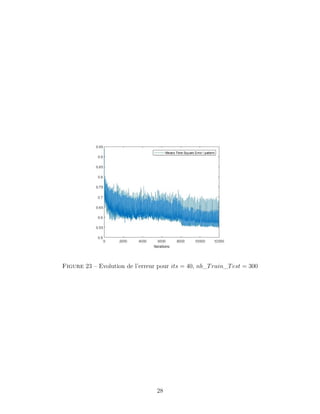
Means Square Error per pattern
L’algorithme nntrain renvoie une variable es : l’erreur au sens des moindres carrés ramenée
au nombre d’exemples. Elle est calculée à chaque itération donc on peut tracer son évolution
au cours du temps.
Success rate
J’ai écrit un petit algorithme (performance) qui, à l’issu de la validation (nntest), récupère
la sortie du réseau pour chaque échantillon qui y est entré (censé être proche d’un nombre
parmi {0.1, 0.2, 0.3, 0.4, 0.5}, le multiplie par 10 et l’arrondi à l’entier le plus proche. De
cette manière, le nombre obtenu devrait appartenir au multiplet {1, 2, 3, 4, 5}. Le programme
récupère également la classe de l’échantillon correspondant (contenu dans la dernière colonne
de V ) et il compte le nombre de fois que le réseau de neurones avait prédit le bon résultat.
On obtient un taux de réussite par phase de validation : on peut alors tracer son évolution
au fil des alternances correction/validation.
En parallèle, algorithme performance simule l’effet d’un tirage aléatoire d’un nombre
appartenant à {1, 2, 3, 4, 5} autant de fois qu’il y a d’échantillons. Son taux de succès est
calculé de la même manière ainsi on pourrait voir si le réseau fait une prédiction meilleure
qu’une personne proposant au hasard une prédiction du résultat. Cependant, contrairement
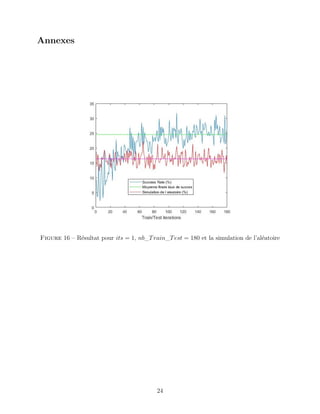
à mon attente, la valeur moyenne du taux de succès de cet algorithme n’est pas de 20% mais
plutôt de 16% et cette valeur est régulière. La figure 16 montrant ce phénomène se trouve en
annexe.
13](https://image.slidesharecdn.com/rapportia-190510130451/85/Rapport-projet-Master-2-Intelligence-Artificielle-15-320.jpg)