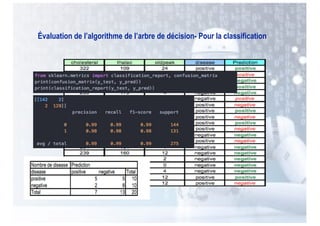
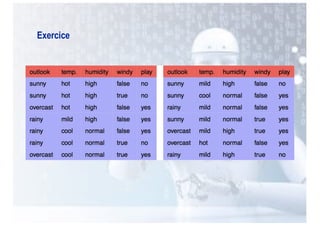
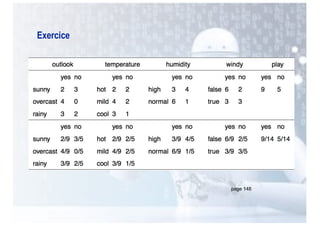
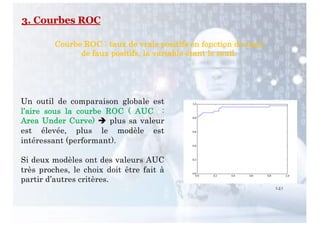
Le chapitre aborde l'apprentissage supervisé, définissant ses principes fondamentaux et ses algorithmes, notamment les k plus proches voisins (k-PPV) et les arbres de décision. Ces algorithmes visent à construire des modèles prédictifs basés sur des exemples étiquetés, en tirant parti de différentes représentations de données et en adaptant leur complexité selon la nature des problèmes. Les performances et l'efficacité des méthodes dépendent de choix cruciaux tels que la distance dans k-PPV et la sélection des attributs dans les arbres de décision.














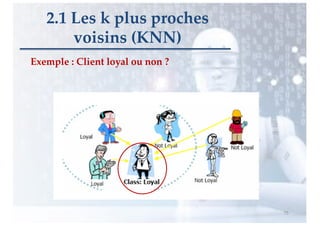

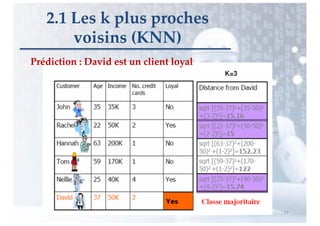
![Exercice sur l’algorithme des k plus proches voisins
Nous considérons le problème de classification
binaire où l’espace des entrées est X = [0; 1] et
l’espace des sorties est {0; 1}.
La base d’apprentissage est (X1 = 0, 8 ; Y1 = 1),(X2 =
0, 4 ; Y2 = 0),(X3 = 0, 7 ; Y3 = 1).
Donner la valeur prédite pour toute nouvelle entrée
x ∈ X
(a) par l’algorithme des 3-p.p.v.
(b) par l’algorithme du p.p.v
78
2.1 Les k plus proches
voisins (KNN)](https://image.slidesharecdn.com/apprentissagesupervise-230110185723-f33eb747/85/Apprentissage-supervise-pdf-17-320.jpg)







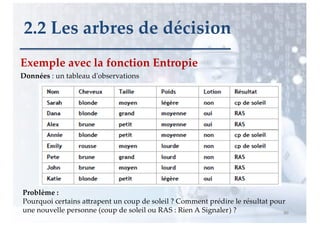
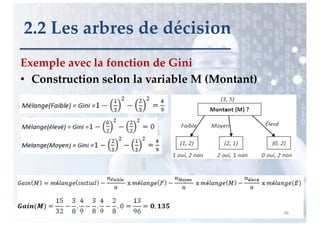
![Exemple avec la fonction Entropie
87
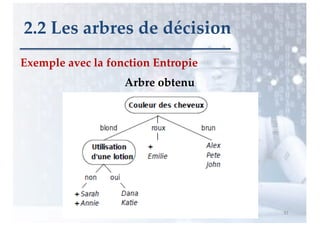
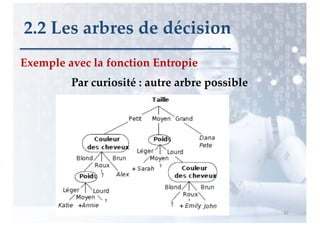
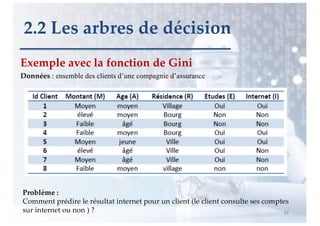
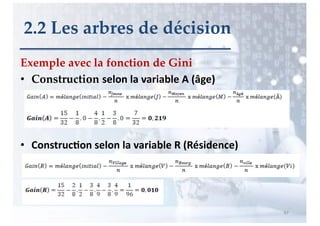
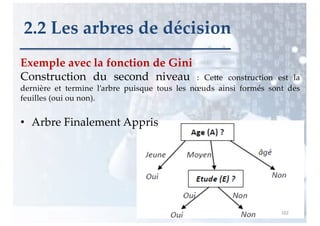
2.2 Les arbres de décision
E = ensemble des 8 exemples
entropie(E) = - 5/8 log2 (5/8) - 3/8 log2 (3/8) = 0.42 + 0.53 = 0.95
Entcroisee(Taille)
= prob(petit)*entropie(E, petit) +
prob(moyen)* entropie(E, moyen) +
prob(grand)* entropie(E, grand)
= 3/8 [ -1/3*log2 (1/3) –2/3*log2 (2/3) ] +
3/8 [ -1/3*log2 (1/3) –2/3*log2 (2/3) ] +
2/8 [ -1*log2 (1) –0*log2 (0) ]
= 0.344 + 0.344 + 0 = 0.69](https://image.slidesharecdn.com/apprentissagesupervise-230110185723-f33eb747/85/Apprentissage-supervise-pdf-26-320.jpg)