Télécharger en tant que PDF, PPTX























































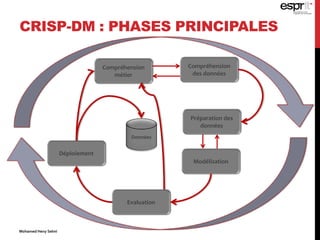






![TRANSFORMATION DES
DONNÉES
Transformez le numérique à des échelles numériques
Les échelles salariales de « 100 TND » à « 1000 TND » à un
certain nombre de [0.0, 1.0]
Le système métrique (par exemple, le mètre, kilomètre) au
système anglais (par exemple, des pieds et miles)
Recoder les données catégoriques à des échelles
numériques
"1" = "oui" et "0" = "No"
Mohamed Heny Selmi](https://image.slidesharecdn.com/datamining-introductiongnrale-160229201502/85/Data-mining-Introduction-generale-83-320.jpg)













Le document traite de la fouille de données (data mining) et de ses techniques, en détaillant les méthodes d'analyse, de classification, de segmentation et leur application dans divers domaines comme le marketing et la finance. Il présente aussi le processus d'extraction de connaissances à partir de bases de données, ainsi que les méthodologies de travail comme KDD et SEMMA. En somme, ces outils aident à transformer des données brutes en informations utiles pour la décision stratégique.













































![Data Mining [JePartage]](https://cdn.slidesharecdn.com/ss_thumbnails/dm-170924183818-thumbnail.jpg?width=640&height=640&fit=bounds)

