Télécharger en tant que PDF, PPTX






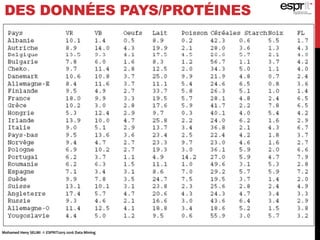


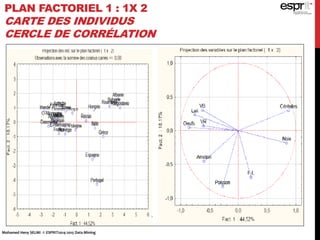
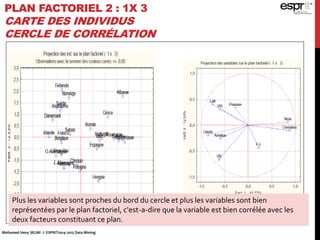
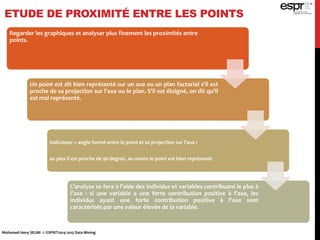


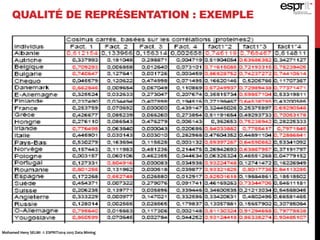
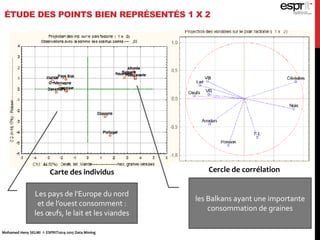
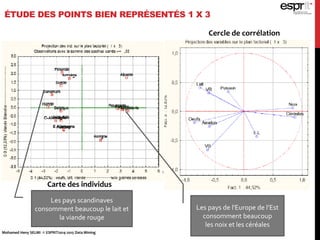
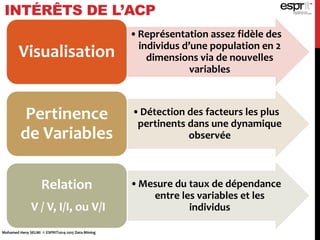
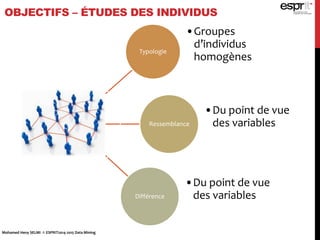




L'analyse en composantes principales (ACP) est utilisée pour réduire la dimensionnalité des données tout en minimisant la perte d'information, permettant une visualisation des données dans un espace 2D. Les critères comme le critère de Kaiser et le critère du coude sont employés pour sélectionner le nombre d'axes factoriels à retenir, représentant ainsi la majorité de l'inertie totale. L'ACP permet également d'identifier les corrélations entre les variables et de grouper des individus ayant des caractéristiques similaires.




































![Ch4 andoneco [mode de compatibilité]](https://cdn.slidesharecdn.com/ss_thumbnails/ch4andonecomodedecompatibilit-140429111854-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










