Téléchargé 96 fois












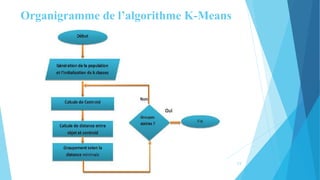


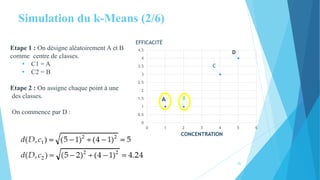









Le document traite de la segmentation par clustering, en présentant notamment l'algorithme k-means, qui permet de regrouper des objets similaires. Il aborde la définition de la segmentation, les critères d'un bon regroupement, les mesures de similarité, ainsi que les domaines d'application et les variantes de k-means. Enfin, il souligne les avantages et inconvénients de cette méthode en matière de classification non supervisée.












































![[PFE] Design and implementation of an AoA, AS and DS estimator on FPGA-based...](https://cdn.slidesharecdn.com/ss_thumbnails/yassineselmipfeinrs-160223194658-thumbnail.jpg?width=640&height=640&fit=bounds)



































