Téléchargé 735 fois






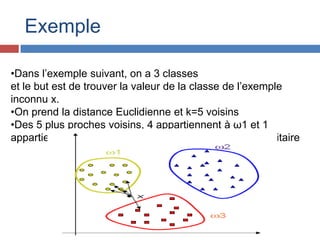








Le document présente la méthode des k plus proches voisins (k-NN), une technique d'apprentissage supervisé utilisée principalement pour la classification dans divers domaines tels que la reconnaissance de formes et le marketing ciblé. Il décrit son principe de fonctionnement, basé sur la proximité des données via des mesures de distance, et souligne ses avantages, comme la simplicité, ainsi que ses inconvénients, tels que la lenteur des prédictions et la sensibilité au bruit. En conclusion, il mentionne d'autres algorithmes de data mining comme les arbres de décision et les réseaux de neurones.



























![Comprendre l’intelligence artificielle [webinaire]](https://cdn.slidesharecdn.com/ss_thumbnails/technologiawebinaireintelligenceartificielleclaudemarson01042019-190403213713-thumbnail.jpg?width=640&height=640&fit=bounds)



















