Téléchargé 226 fois








![Distances (données
numériques)
Distance de Minkowsky :
d(w1, w2) = [ Σj=1p |x1j – x2j|λ ] 1/λ
pour λ = 1, on a les valeurs absolues (distance de
Manhattan)
pour λ = 2, on a la distance euclidienne simple (M = I)
pour λ +∞, on obtient la distance de Chebyshev
(ultramétrique):
d(w1, w2) = Max j |x1j – x2j|
8](https://image.slidesharecdn.com/5-clustering-121218064208-phpapp01/85/clustering-8-320.jpg)









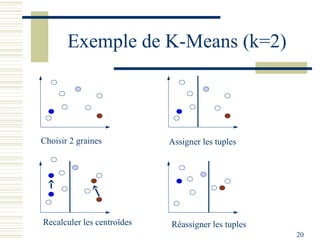
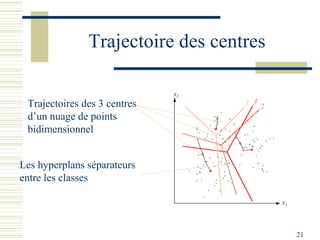
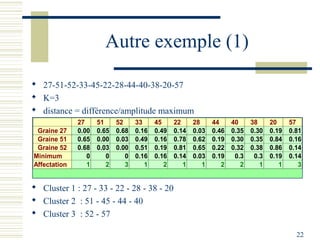









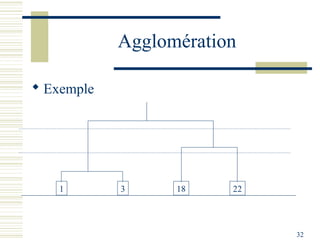

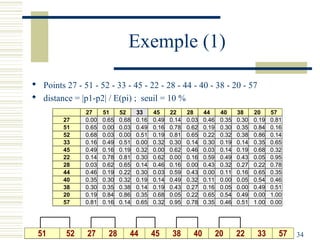




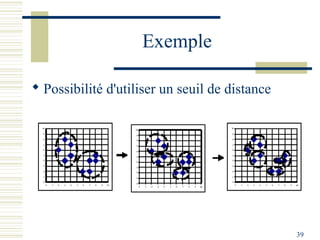












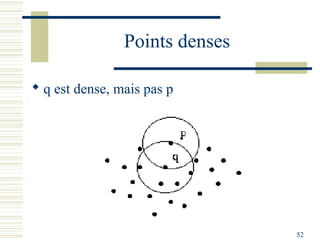


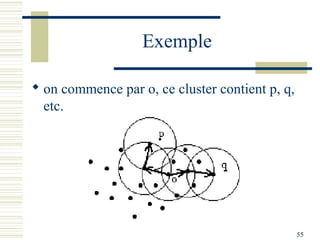
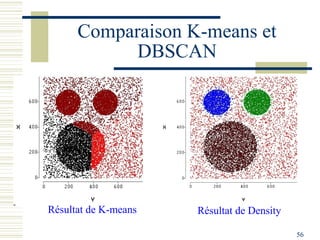








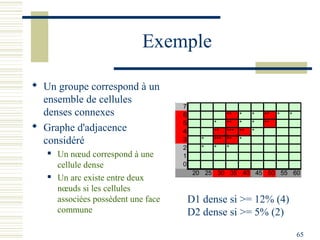


Le document décrit les méthodes de groupement (clustering) utilisées pour la classification automatique d'objets, en mettant l'accent sur les objectifs, les distances et les différents algorithmes tels que le k-means et les méthodes hiérarchiques. Il explore les concepts de similarité et de dissimilarité, ainsi que diverses approches pour mesurer les distances entre les données, que ce soit pour des données numériques ou qualitatives. Enfin, il aborde les forces et faiblesses de chaque méthode, y compris des descriptions détaillées des algorithmes de partitionnement et hiérarchiques.



































































