Téléchargé 361 fois




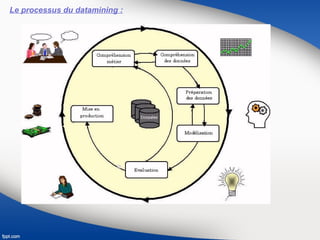





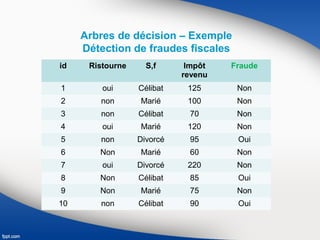
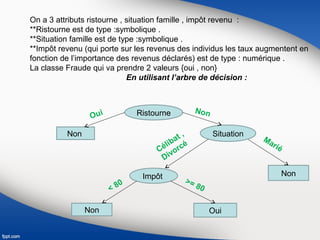
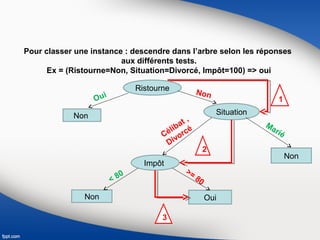


Le document présente une vue d'ensemble du data mining, soulignant son évolution depuis les années 1990 et son utilisation dans divers secteurs tels que la santé, la finance et le marketing. Il explique également les processus de data mining, y compris les différentes phases de compréhension, préparation, modélisation, évaluation et déploiement des données, ainsi que les techniques d'apprentissage supervisé et non supervisé. Enfin, il décrit plusieurs algorithmes spécifiques utilisés dans ces techniques, comme les arbres de décision et les méthodes de clustering.























































