Téléchargé 372 fois






















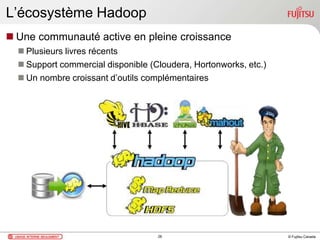









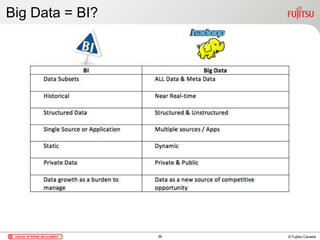



Ce document présente une introduction au concept de Big Data et à la solution Hadoop, en détaillant ses caractéristiques, son écosystème et les principaux acteurs de l'industrie. Il aborde les défis associés au traitement des données à grande échelle ainsi que les cas d'utilisation dans divers secteurs, tels que les ventes en ligne et la détection de fraude. Enfin, il conclut en soulignant l'importance de Hadoop comme technologie évolutive et accessible pour le traitement de Big Data.











































































