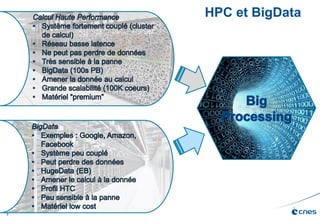
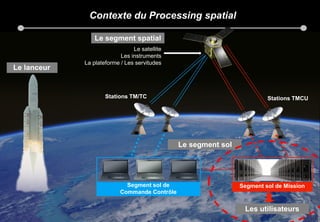
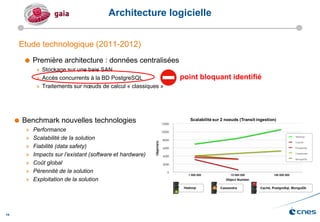
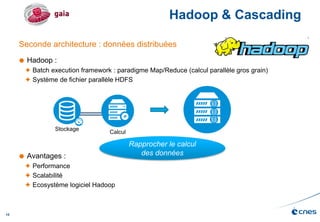
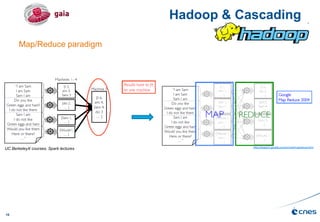
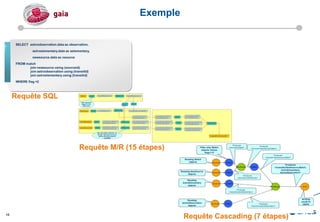
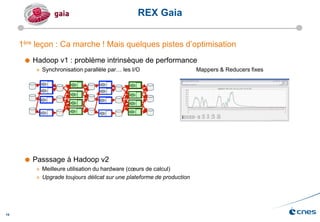
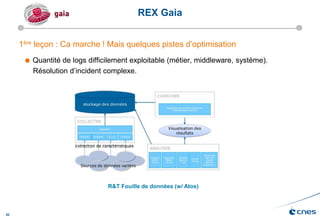
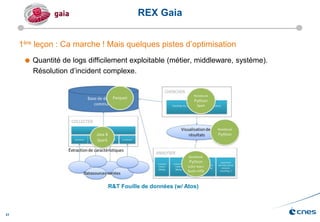
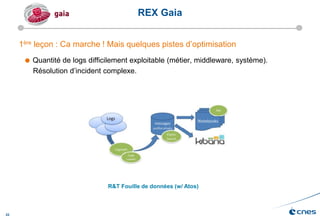
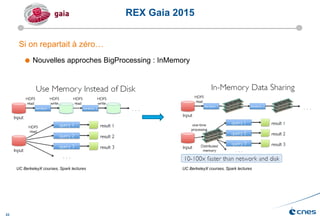
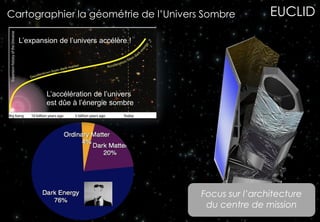
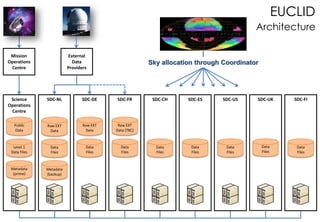
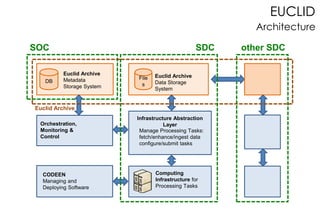
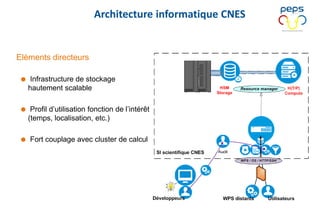
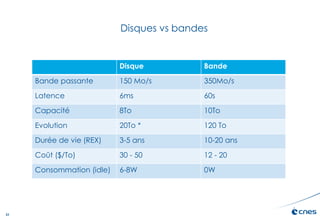
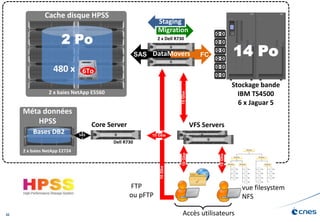
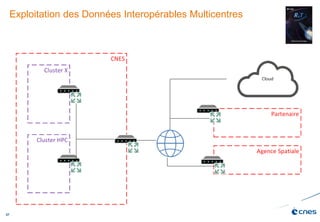
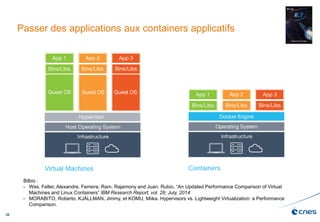
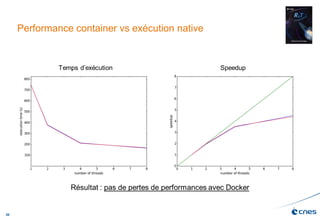
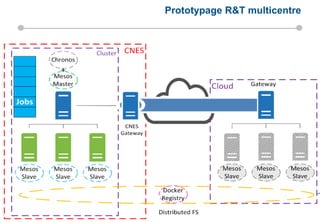
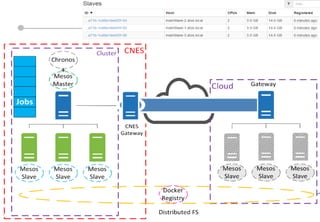
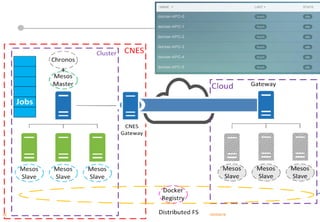
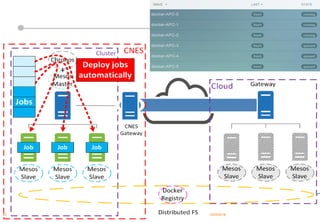
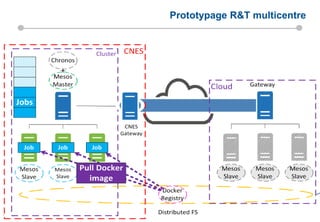
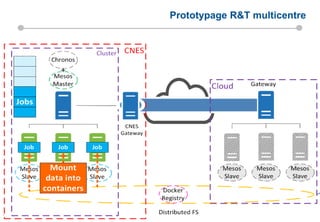
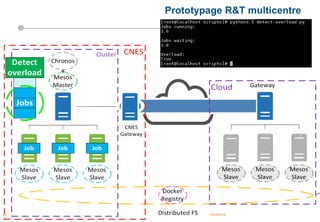
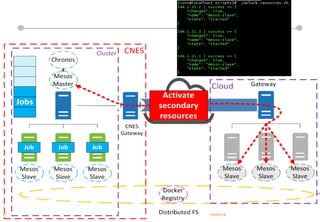
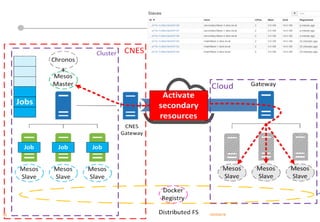
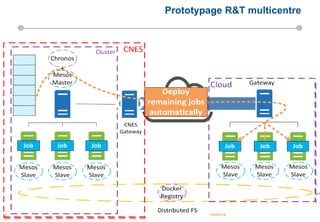
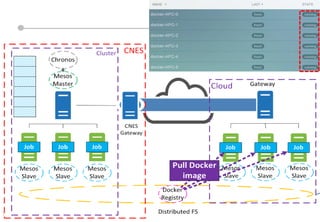
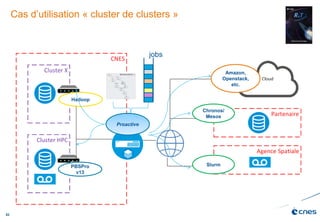
Le document présente les enjeux et les stratégies du pôle HPC du CNES autour du big data et du big processing, en mettant l'accent sur l'interopérabilité entre différents centres de calcul et les architectures de traitement des données. Il aborde des projets tels que Gaia et Euclid, soulignant les défis techniques et les innovations en matière de stockage et de traitement. Enfin, le document conclut sur l'importance de centrer les algorithmes au cœur des plateformes pour maximiser leur valeur ajoutée.