Télécharger pour lire hors ligne



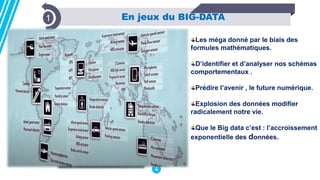






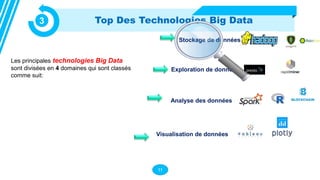








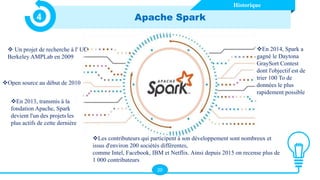

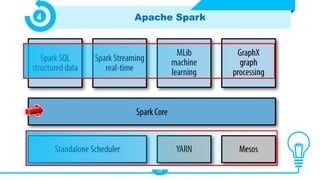
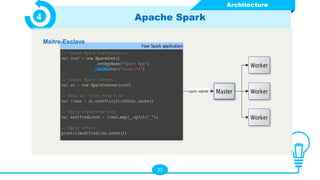

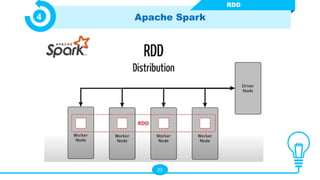
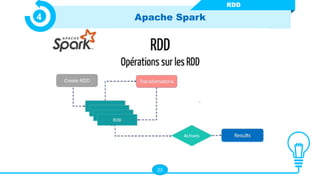





Le document présente les technologies du big data, en détaillant leurs types, applications et avantages, notamment à travers des outils comme Hadoop, Presto, Spark, et TensorFlow. Il met en évidence l’importance du big data pour analyser des ensembles de données massifs en temps réel pour la prise de décision. Apache Spark est particulièrement mis en avant pour ses capacités de traitement rapide et ses fonctionnalités d'intégration avec d'autres technologies big data.















































