Télécharger pour lire hors ligne







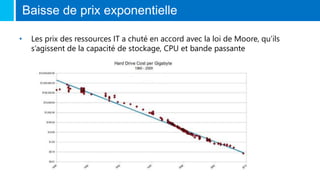






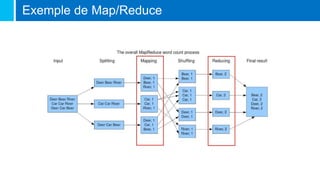

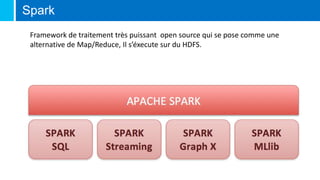










Le document traite de la Big Data, définie comme un ensemble de données volumineux que les outils classiques ne peuvent traiter, et de ses caractéristiques clés : volume, variété et vélocité. Il discute des mouvements NoSQL et des technologies développées par des géants du web pour gérer ces données, ainsi que des différents types de bases de données NoSQL. Enfin, il met en avant les métiers liés à la Big Data, tels que Chief Data Officer, Data Scientist, et l'importance du machine learning dans l'analyse des données.





































































