Téléchargé 114 fois













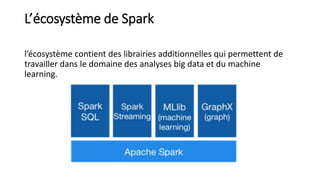
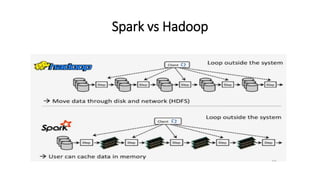


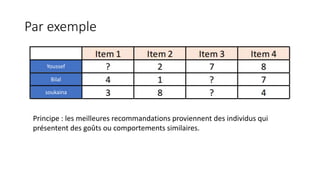
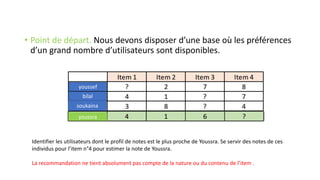



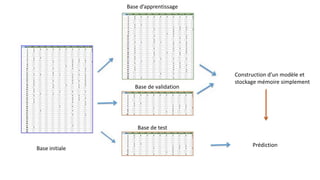


Le document traite de la création d'un système de recommandation de films utilisant des technologies comme Hadoop, Spark et Flask. Il aborde les défis liés au choix des consommateurs et les étapes nécessaires pour établir un modèle de filtrage collaboratif, ainsi que les technologies sous-jacentes et les concepts clés. Une démo est prévue pour illustrer l'application du modèle avec un jeu de données de 21 millions de notes attribuées à des films.








































































