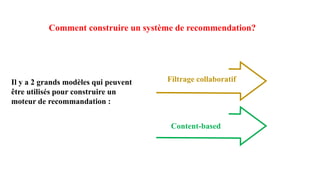
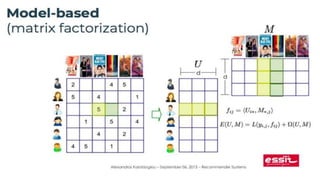
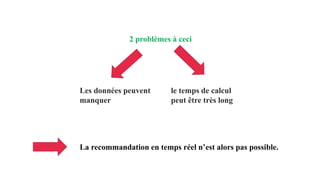
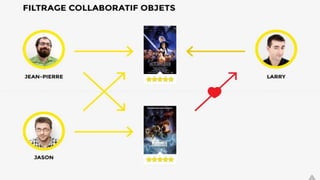
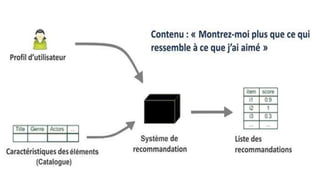
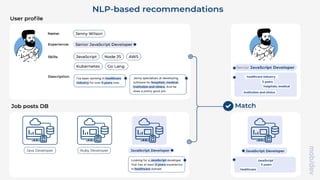
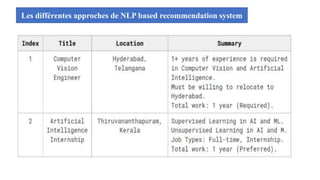
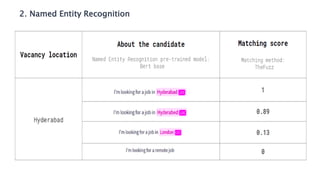
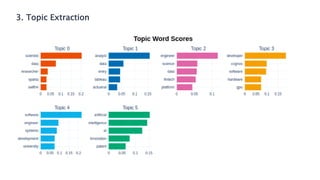
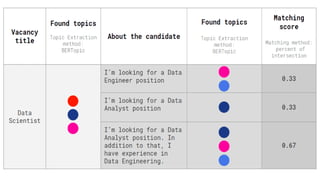
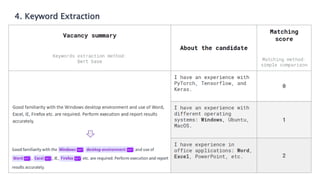
Le document présente les systèmes de recommandation, qui filtrent les informations pour suggérer des éléments aux utilisateurs en fonction de leurs préférences. Deux principaux modèles de recommandation sont évoqués : le filtrage collaboratif et l'approche content-based, ainsi que d'autres modèles tels que les recommandations basées sur la popularité ou aléatoires. Il aborde également les processus de construction d'un moteur de recommandation et les différentes techniques utilisées pour analyser les contenus et les préférences des utilisateurs.