Ce document traite des systèmes de recommandation dans le commerce électronique, en mettant l'accent sur le filtrage collaboratif comme méthode prometteuse pour aider les utilisateurs à naviguer parmi de nombreux choix. Il aborde les défis de la construction d'un système efficace, notamment la nécessité d'identifier des voisins similaires pour faire des prédictions précises, et présente deux approches de recommandation. Le rapport explore également les problèmes de parcimonie et les solutions potentielles pour améliorer la précision des recommandations.


![110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
Movie Recommendation system
2. ´Etat de l’art
Le probl`eme de recommandation d’items dans certaines
bases de donn´ees ”fixes” a ´et´e largement ´etudi´e, et deux
paradigmes principaux ont ´emerg´e. Dans le ”content-based
recommandation” on essaie de recommander des articles
similaires `a ceux qu’un utilisateur donn´e a aim´es par le
pass´e, alors que dans la recommandation collaborative, on
identifie les utilisateurs dont les goˆuts sont similaires `a ceux
de l’utilisateur donn´e, par la suite le syst`eme recommande
les articles qu’ils ont aim´es.
Les syst`emes mettant en œuvre les approches de recom-
mandation bas´ees sur le contenu consistent `a analyser un
ensemble de documents ou de descriptions d’´el´ements et de
construire un mod`ele ou un profil repr´esentatif des int´erˆets
des utilisateurs sur la base de caract´eristiques d’articles
pr´ec´edemment not´es par un utilisateur.
Le profil est une repr´esentation structur´ee des int´erˆets
des utilisateurs, utilis´e pour recommander de nouveaux
´el´ements int´eressants. Le processus de recommandation
consiste donc essentiellement `a faire correspondre les at-
tributs du profil de l’utilisateur aux attributs d’un article. Le
r´esultat est un jugement pertinent qui repr´esente le niveau
d’int´erˆet de l’utilisateur pour cet article. L’objectif est donc
alors de cerner et de comprendre les motivations ayant con-
duit l’utilisateur `a juger comme pertinent ou non un item
donn´e.
Cependant, le ”content-based” montre certains limites.
Parmi ces inconv´enients nous citerons:
• Analyse limit´ee du contenu: si le contenu ne contient
pas suffisamment d’informations pour discriminer les
´el´ements de mani`ere pr´ecise, la recommandation ne
sera pas efficace `a la fin.
• Les m´ethodes bas´ees sur le contenu fournissent un
degr´e de ”nouveaut´e” assez limit´e, car le but est de
faire correspondre les caract´eristiques des profils avec
celles des items. Par cons´equent le ”content-based fil-
tering” quasi parfait ne sugg`ere rien de ”surprenant.”
• Nouvel utilisateur: quand il n’y a pas suffisamment
d’informations pour ´etablir un profil solide pour un
utilisateur, la recommandation ne peut ˆetre fournie de
mani`ere correcte.
C’est pour ces raisons que nous avons opt´e pour
l’impl´ementation des m´ethodes de recommandation
collaboratives.
Les syst`emes de recommandation bas´es sur le filtrage col-
laborative est un sujet bien ´etudi´e. Ces syst`emes essayent
de pr´edire les notes de certains articles pour un utilisateur
cible en se basant sur les articles d´ej`a not´es par d’autres
utilisateurs [1] et ce en utilisant une mesure de similarit´e
bien d´efinie. LikeMinds [2] est une des applications
les plus populaires qui utilise le filtrage collaborative.
L’algorithme utilis´e prend en entr´ee un utilisateur cible
ainsi qu’un ensemble d’utilisateurs candidats, et calcule
la similarit´e en se basant sur la diff´erence entre les notes
donn´ees par l’utilisateur cible, et celles des candidats.
Le candidat ayant le score de similarit´e le plus haut est
consid´er´e comme ´etant un mentor pour l’utilisateur cible.
Les notes de ce dernier sont par la suite calcul´ees en se
basant sur les notes du mentor.
3. Probl`eme de parcimonie
Un probl`eme de complexit´e se pose en raison du nom-
bre important de notes que le syst`eme doit traiter. Cepen-
dant, pour la plupart des syst`emes de recommandations, le
fait d’avoir peu de notes repr´esente un probl`eme de plus
grande importance. Ce probl`eme se pose lorsqu’un nom-
bre cons´equent d’articles est propos´e. En effet, proportion-
nellement `a la taille du stock disponible, un nombre r´eduit
d’articles est ´evalu´e et ce par un nombre r´eduit d’utilisateur.
Par cons´equent seul un pourcentage faible de la totalit´e des
articles est not´e. Dans cette situation, il est difficile de trou-
ver des utilisateurs qui partagent les mˆemes articles. Ce
ph´enom`ene est plus connu sous le nom de probl`eme de
parcimonie. Par cons´equent diff´erentes solutions ont donc
´et´e propos´ees afin d’y rem´edier. Parmi elles on retrouve :
• Description du contenu : Le descriptif des articles per-
met d’augmenter la quantit´e d’information de mani`ere
g´en´erale, mais en particulier celle que les utilisa-
teurs ont en commun. Cependant, l’utilisation des
m´ethodes collaboratives ont montr´e leur efficacit´e par
rapport aux m´ethodes bas´ees sur le contenu.
• ´Evaluations implicites : Certains syst`emes essaient
d’augmenter le nombre d’´evaluations d’un utilisa-
teur en se basant sur son comportement. Cependant,
l’utilisateur doit imp´erativement explorer l’article
avant que le syst`eme puisse en d´eduire la note.
• R´eduction de la dimension : En r´eduisant la dimen-
sion de l’espace d’information, les notes de deux util-
isateurs peuvent ˆetre utilis´ees pour les pr´edictions,
mˆeme s’ils ne partagent pas les mˆemes articles. Paz-
zani et Billsus [3] ont propos´e une m´ethode de
pr´ediction bas´ee sur l’utilisation des r´eseaux de neu-
rones au lieu de la corr´elation, o`u les notes des utilisa-
teurs sont repr´esent´ees par des matrices bool´eennes.
Ces matrices sont par la suite projet´ees dans un es-
pace de dimension r´eduite en utilisant l’indexation
s´emantique latente. Cette approche bien qu’elle soit
efficace fait face `a un probl`eme important qui est la
complexit´e computationnel.](https://image.slidesharecdn.com/qgnduxzsro2wdk67motr-signature-e43c35fa3f0960967d3d76643ab96bbdf6c36b7e6d013c95e51290d1174e0c6b-poli-171205110954/85/Movie-Recommendation-system-2-320.jpg)
![220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
Movie Recommendation system
4. Basline
Nous pr´esentons tout d’abord les m´ethodes de pr´ediction
de base. Ces m´ethodes sont utiles pour ´etablir des base-
lines non personnalis´ees contre lequel des algorithmes per-
sonnalis´es peuvent ˆetre compar´es. Les algorithmes de base
ne d´ependent pas des notes des utilisateurs et peuvent ˆetre
utiles pour fournir des pr´edictions concernant de nouveaux
utilisateurs. Nous notons une pr´ediction de base d’un util-
isateur u et un article i par bu,i. L’algorithme de base le
plus simple est de pr´edire la note moyenne parmi toutes les
´evaluations dans le syst`eme : bu,i = m ( o`u m est la note
moyenne globale ). Ceci peut ˆetre am´elior´e en pr´edisant
la note moyenne attribu´ee par l’utilisateur bu,i = ru ,
pour cet article bu,i = ri. Cette baseline peut ˆetre encore
am´elior´ee en combinant la moyenne de l’utilisateur avec
l’´ecart moyen de la moyenne des notes que l’utilisateur a
attribu´e `a un article sp´ecifique. En g´en´eral, une baseline de
la forme suivante peut ˆetre utilis´ee:
bu,i = m + bu + bi
O`u bu, bi sont les pr´edicteurs de base des utilisateurs et
d’articles respectivement. Ces pr´edicteurs peuvent ˆetre
d´efinis en utilisant simplement la moyenne des d´ecalages
(offsets) de la fac¸on suivante:
bu = 1
|Iu| ΣiεIu (ru,i − m)
bi = 1
|Ui| ΣuεUi
(ru,i − bu − m)
Cette baseline peut encore ˆetre am´elior´ee et ce en four-
nissant une estimation plus raisonnable des pr´ef´erences des
utilisateurs face `a un ´echantillonnage parcimonieux. Cela
est fait en introduisant les deux variables βu et βi [4]:
bu = 1
|Iu|+βu
ΣiεIu
(ru,i − m)
bi = 1
|Ui|+βi
ΣuεUi
(ru,i − bu − m)
Cet ajustement permet d’avoir une note proche de la
note moyenne globale lorsqu’un utilisateur n’a not´e que
quelques articles, ou si un article n’a pas ´et´e not´e par
plusieurs utilisateurs. Notre choix s’est port´e sur cette
baseline en raison de son efficacit´e [4].
5. Calcul de la similarit´e
Le filtrage collaborative est bas´e essentiellement sur la
mesure de la similarit´e, d’o`u l’importance d’utiliser un
algorithme efficace. Diff´erentes m´ethodes sont utilis´ees
et permettent de calculer g´en´eralement la distance ou la
corr´elation entre 2 vecteurs.
5.1. Distance de Manhattan:
La distace de Manhattan est l’une des m´ethodes les plus
simples pour mesurer la distance entre deux points associ´ee
`a la norme1. Ayant deux point x et y, la distance entre les
deux est d´efinie par:
d(x, y) = Σn
k=1 | xk − yk |
5.2. Distance Euclidienne
Plus intuitive que la distance de Manhattan, la dis-
tance euclidienne est consid´er´ee comme ´etant la distance
g´eom´etrique dans un espace multidimensionnel. Elle est
calcul´ee en utilisant la formule :
d(x, y) = Σn
k=1(xk − yk)2
5.3. Pearson Correlation Coefficient PCC
Ce coefficient est plus complexe que la distance euclidi-
enne et la distance Manhattan mais obtient g´en´eralement
de meilleurs r´esultats avec des donn´ees non normalis´ees.
C’est le cas par exemple lorsque nous avons des utilisateurs
qui donnent seulement des mauvaises notes et d’autres qui
ne donnent que des bonnes notes. La PCC mesure le nom-
bre de fois ou deux variables changent ensemble divis´e par
le produit du nombre de fois o`u celles-ci changent individu-
ellement. Plus les variables changent ”ensembles” par rap-
port `a la fac¸on dont elles changent individuellement, plus
elles sont corr´el´ees.
pearson(x, y) =
Σn
k=1(xk−¯x)(yk−¯y)
√
Σn
k=1
(xk−¯x)2Σn
k=1
(xy−¯y)2
5.4. Cosinus
La similarit´e cosinus (ou mesure cosinus) permet de cal-
culer la similarit´e entre deux vecteurs `a n dimensions en
d´eterminant le cosinus de l’angle entre eux. La formule
utilis´ee est :
cos(Θ) = x.y
x ∗ y
Dans notre cas, nous avons opt´e pour l’utilisation de la
mesure PCC afin de calculer la similarit´e entre les articles.
6. Approches impl´ement´ees
Le but de ce projet est d’impl´ementer deux m´ethodes bas´ee
recommandation collaborative. Dans ce rapport de mi-
parcours les filtrages bas´es item-item et item-user ont ´et´e
impl´ement´e et sont pr´esent´es dans ce qui suit :](https://image.slidesharecdn.com/qgnduxzsro2wdk67motr-signature-e43c35fa3f0960967d3d76643ab96bbdf6c36b7e6d013c95e51290d1174e0c6b-poli-171205110954/85/Movie-Recommendation-system-3-320.jpg)

![440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
Movie Recommendation system
nique pr´ec´edente, mais au lieu d’utiliser les notes brutes
Ru,N de l’item similaire N, cette approches utilise leurs
approximation Ru,N en se basant sur un mod`ele lin´eaire.
Si nous notons les vecteurs respectifs de l’item cible i et
l’item similaire N par Ri et RN , le mod`ele de r´egression
linaire peut ˆetre formul´e comme suit :
RN = αRi + β +
Les param`etres de la r´egression linaire α et β sont `a
d´eterminer `a partir des deux vecteurs de notes. est l’erreur
du mod`ele de r´egression.
Nous avons opt´e pour l’utilisation de la deuxi`eme m´ethode
qui permet de palier aux probl`emes qui peuvent avoir lieux
en utilisant la mesure de similarit´e PCC.
6.1.3. PREMI `ERES EXP ´ERIMENTATIONS
Les donn´ees sur lesquelles nous avons lanc´e nos algo-
rithmes sont extraites d’une comp´etition Kaggle [4]. Cette
base contient un ensemble de films choisit al´eatoirement
et not´e par un ensemble d’utilisateurs. Ces notes varient
entre 0 et 5. Chaque instance dans la base est repr´esent´ee
par un tripl´e (userid, movieid, rating) o`u le nombre total
d’instances est 4 000 056, ce qui repr´esente seulement 2%
des notes possibles.
Nous commenc¸ons tout d’abord par identifier les films les
plus not´es en les affichant par ordre d´ecroissant, cela nous
permet d’avoir une id´ee sur les articles qui peuvent nous
apporter des informations utiles. Le tableau ci-dessous
repr´esente les cinq premiers articles les plus not´es :
Table 1. Les films les plus populaires
FILM NOMBRE DES NOTES
AMERICAN BEAUTY 1684
STAR WARS: EPISODE V 1585
STAR WARS: EPISODE IV 1573
BACK TO THE FUTURE 1396
THE MATRIX 1373
De la mˆeme mani`ere, nous poursuivons par l’extraction des
identifiants des utilisateurs les plus actifs (ayants attribuer
le plus des notes). Ces derniers sont les utilisateurs qui
peuvent nous apporter le maximum de gain d’informations
sur les films.
Table 2. Les utilisateurs les plus actifs
ID DE L’UTILISATEUR NOMBRE FILMS NOT ´ES
3618 1344
5795 1272
4344 1271
4510 1240
4227 1222
Prenons par exemple les deux films : ”The Empire Strikes
Back” (1980) et ”Return of the Jedi” (1983). Afin de
mesurer leur corr´elation, nous proc´edons par l’extraction
des utilisateurs ayants not´e ces derniers. Nous remarquons
que parmi les utilisateurs, 1167 utilisateurs ont not´e les
deux films. Dans ce cas, chaque film sera d´ecrit par un
vecteur de dimension ´egale `a 1167, ou chaque ´el´ement i
repr´esente une note attribu´e par un utilisateur i. Ainsi, La
corr´elation calcul´ee ente les deux films est ´egale `a 0.73 ce
qui indique qu’ils sont similaires.
Nous ´etendons notre syst`eme afin de calculer la similarit´e
entre chaque paire de films dans notre base. Le tableau ci-
dessous repr´esente les cinq premiers r´esultats de calcule de
corr´elation entre les films :
Table 3. Les films les plus similaires
FILM A FILM B CORR ´ELATION
RET. OF THE JEDI EMP. STRIKES BACK 0.787
STAR TREK STAR TREK III 0.758
STAR TREK STAR TREK V 0.720
STAR WARS RET. OF THE JEDI 0.687
STAR TREK VI STAR TREK III 0.635
Ces mesures de corr´elation nous permettent d’avoir plus
d’information sur les films. Par exemple, les utilisateurs qui
ont aim´e Return of the Jedi vont aussi aimer Empire Strikes
back et vice versa, les utilisateurs qui n’ont pas donn´e de
bonne notes au premier film, vont donner une mauvaise
note au second.
Nous avons aussi remarqu´e que bien que les deux s´eries
StarWars et StarTrek appartiennent `a la mˆeme cat´egorie,
la mesure de similarit´e entre les deux est faible ( 0.08
entre Star Trek V et Empire Strikes back par exemple).
Cela implique que l’utilisation des m´ethodes collaboratives
nous permet d’exploiter d’autres caract´eristiques permet-
tant d’avoir des informations plus pertinentes sur les arti-
cles qu’en se basant uniquement sur le contenu des films
par exemple. En effet, visiblement les utilisateurs ayant
aim´e StarWars ne recommanderaient pas les StarTrek
Il est donc possible de recommander des films aux utilisa-](https://image.slidesharecdn.com/qgnduxzsro2wdk67motr-signature-e43c35fa3f0960967d3d76643ab96bbdf6c36b7e6d013c95e51290d1174e0c6b-poli-171205110954/85/Movie-Recommendation-system-5-320.jpg)
![550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
Movie Recommendation system
teurs n’ayant jamais vu ces films. Prenons par exemple un
utilisateur ayant donn´e une bonne note `a StarWars V, les
films les plus similaires qui vont ˆetre recommand´e `a celui-
ci sont repr´esent´es par la figure ci dessous:
Figure 1. Les films les plus corr´el´es avec StarWars V.
Concernant la m´ethode de filtrage collaboratif ’Memory-
Based’ bas´ee item-item traditionnelle d´ecrite jusqu’`a
pr´esent, la structure des descripteurs est sous la forme
d’un vecteur multidimensionnel. Avec ce point de vue,
cependant, les vecteurs sont de tr`es grande dimension.
L’´etape suivante de ce projet kaggle est d’impl´ementer
la m´ethode bas´ee user-item en utilisant la technique de
factorisation matricielle (SVD). En raison de la complexit´e
computationnelle de la m´ethode bas´ee item-item, le choix
d’une m´ethode de factorisation s’est donc impos´e de
lui-mˆeme afin d’acc´el´erer le traitement et ce en appliquant
une r´eduction de dimension.
6.2. Model-Based Collaborative Filtering
Les m´ethodes de collaboration Memory based utilisent
la corr´elation entre une paire d’items dans le cas item-
item, ou une paire d’utilisateurs dans le cas user-user.
Ce m´ecanisme utilise les notes attribu´ees par les utilisa-
teur afin de calculer les similarit´es entre les utilisateurs
ou items. Cependant, les m´ethodes collaboratives Model
based utilisent les informations RS afin de g´en´erer les
pr´ediction. Contrairement au m´ethodes Memory based, ces
m´ethodes n’utilisent pas l’int´egralit´e de la base de donn´ees
pour calculer les pr´ediction des donn´ees r´eelles.
Il existe plusieurs algorithmes de filtrage collaboratif : les
Models based tels que Les r´eseaux bay´esiens, les mod`eles
de clustering, les ”Latent Semantic Models” tels que la
d´ecomposition en valeurs singuli`eres (SVD), l’analyse en
composantes principales (PCA) et la factorisation ma-
tricielle probabiliste pour la r´eduction de dimension de la
matrice contenant les notes des utilisateurs.
6.2.1. FACTORISATION MATRICIELLE
Les premiers algorithmes de filtrage collaboratif pour les
syst`emes de recommandation ´etaient bas´es sur l’inf´erence
d’associations, qui poss`ede une complexit´e temporelle tr`es
´elev´ee et une tr`es faible flexibilit´e (´evolutivit´e). En effet,
les impl´ementations ainsi que les algorithmes de filtrage
collaboratif pour les applications des syst`emes de recom-
mandation sont confront´es `a plusieurs d´efis. Le premier
est la taille des ensembles de donn´ees `a traiter. Le sec-
ond provient de la raret´e de la notation matricielle, ce qui
signifie que pour chaque utilisateur seul un petit nombre
d’´el´ements est not´e. C’est pour cette raison que de nou-
velles m´ethodes plus ´evolutive et plus efficace bas´ees sur
des op´erations matricielles ont ´et´e introduite. En effet, `a
l’aide de ces m´ethodes les d´efis rencontr´es sont mieux pris
en charge par la factorisation matricielle.
La factorisation matricielle joue un rˆole important dans
le filtrage collaboratif pour les syst`emes de recomman-
dation. Cette m´ethode est consid´er´ee principalement
comme ´etant une m´ethode d’apprentissage non supervis´e
pour la d´ecomposition en variable latente et la r´eduction
de dimensionnalit´e. La pr´ediction de notes ainsi que
la recommandation peuvent ˆetre obtenues par un large
´eventail d’algorithmes, tandis que les m´ethodes dites ”
Neighborhood-based Collaborative Filtering ” sont simples
et intuitives. Les techniques de factorisation de matrices
sont g´en´eralement plus efficaces car ces derni`eres permet-
tent de d´ecouvrir les caract´eristiques latentes sous-jacentes
des interactions entre les utilisateurs et les items. C’est
donc un outil math´ematique permettant de manipuler des
matrices, et est donc applicable dans de nombreux domaine
en particulier lorsque l’on d´esire trouver une information
latente contenue au niveau des donn´ees. Parmi les mod`eles
de factorisation bien connus on retrouve SVD et PCA qui
permettent d’identifier les facteurs latents dans le domaine
de la recherche d’information et ce dans le but de faire face
aux d´efis de filtrage collaboratif.
La plupart des mod`eles MF sont bas´es sur le mod`ele
de facteur latent [7]. Cette approche de factorisation
est consid´er´ee comme ´etant l’approche la plus pr´ecise
pour r´eduire le probl`eme des niveaux ´elev´es de parci-
monie dans les bases de donn´ees des syst`emes de recom-
mandation, et ce en utilisant parfois des techniques de
r´eduction de la dimensionnalit´e. Pour ce faire, il est
g´en´eralement n´ecessaire de combiner deux techniques :
une m´ethode bas´ee sur un mod`ele d’indexation s´emantique
latente (LSI) et une m´ethode de r´eduction de la dimen-
sionnalit´e Singular Value D´ecomposition (SVD) [7] [8].
Il est `a noter que les m´ethodes de type SVD et PCA sont
consid´er´ees comme ´etant les techniques bien ´etablies pour
l’identification des facteurs latents dans le domaine de la
recherche d’information. Ces m´ethodes sont donc dev-](https://image.slidesharecdn.com/qgnduxzsro2wdk67motr-signature-e43c35fa3f0960967d3d76643ab96bbdf6c36b7e6d013c95e51290d1174e0c6b-poli-171205110954/85/Movie-Recommendation-system-6-320.jpg)
![660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
Movie Recommendation system
enues populaires et ce en combinant une bonne ´evolutivit´e
i.e. ”scalabilit´e” avec une pr´ecision pr´edictive et offrent
beaucoup de flexibilit´e pour mod´eliser diverses applica-
tions de la vie r´eelle.
6.2.2. M´ETHODOLOGIE
Nous disposons tout d’abord d’un ensemble d’utilisateurs
not´e U, et un ensemble d’items not´e I. Soit R la matrice
de taille |U| × |I| contenant toutes les ´evaluations que les
utilisateurs ont affect´ees aux articles. Le but consiste donc
`a trouver deux matrices, P(|U|×K) et Q(|I|×K) de telle
sorte que leur produit soit ´egal approximativement `a R:
R ≈ P × QT
= R
De cette fac¸on, les mod`eles de factorisation matricielle
mappent les utilisateurs ainsi que les items `a un espace
de facteur latent commun de dimension f et permet donc
de mod´eliser les interactions utilisateur-item comme un
produit interne dans cet espace [9]. Par cons´equent,
chaque ´el´ement i est associ´e `a un vecteur qi ∈ Rf
,
et chaque utilisateur u est associ´e `a un vecteur pu ∈
Rf
. Pour un item donn´e i, les ´el´ements de qi mesurent
l’importance pour lequel cet item poss`ede des facteurs
positifs ou n´egatifs. Le r´esultat du produit point `a point
qT
i pu capture l’interaction entre l’utilisateur u et l’item i,
cela repr´esente donc l’int´erˆet global que porte l’utilisateur
en question aux caract´eristiques de l’item i. Cela permet
donc d’approximer le score que l’utilisateur u attribuerait `a
l’item i qui est d´esign´ee par rij Cela nous m`ene `a estimer:
rij = pT
i qj = Σk
k=1pi,kqk,j
Il s’agit maintenant de trouver un moyen d’obtenir P et Q.
Une approche permettant de r´esoudre ce probl`eme est de
commencer par initialiser les deux matrices `a des valeurs
al´eatoires, calculer `a quel point leur produit est diff´erent de
M, puis de minimiser cette diff´erence it´erativement. Cette
m´ethode est appel´ee descente du gradient et sert `a trouver
le minimum local de la diff´erence.
La diff´erence ici, g´en´eralement appel´ee l’erreur entre la
note estim´ee et la note r´eelle et peut ˆetre calcul´ee en util-
isant la formule suivante pour chaque paire utilisateur-item
:
e2
ij = (rij − rij)2
= (rij − ΣK
k=1pi,kqk,j)2
nous consid´erons l’erreur quadratique car la note estim´ee
peut ˆetre plus grande ou plus petite que la note r´eelle.
Afin de minimiser l’erreur, nous devons savoir dans quelle
direction nous devons minimiser les valeurs de pi,k et qk,j.
Autrement dit, nous devons savoir la direction du gradient
au niveau des valeurs actuelles, et donc il est n´ecessaire de
d´eriver l’´equation ci-dessus par rapport aux deux variables
s´epar´ement :
d
dpi,k
e2
ij = −2((rij − rij)(qk,j) = −2eijqk,j
d
dqk,j
e2
ij = −2((rij − rij)(pi,k) = −2eijpi,k
Ayant le gradient, nous pouvons formuler les r`egles de mise
`a jour de pi,k et qk,j comme suit :
pi,k = pi,k + α d
dpi,k
e2
ij = pi,k + 2αeijqk,j
qk,j = qk,j + α d
dqk,j
e2
ij = qk,j + 2αeijpi,k
Ici, α est une constante dont la valeur d´etermine le pas `a
prendre pour atteindre la valeur minimale. D’une mani`ere
g´en´erale, la valeur de α doit ˆetre petite, en effet, une grande
valeur pourrait ne pas atteindre le minimum.
En utilisant la formule de mise `a jour ci-dessus, nous pou-
vons effectuer l’op´eration de minimisation it´erativement
jusqu’`a ce que l’erreur converge vers son minimum.
Nous pouvons v´erifier l’erreur globale calcul´ee en utilisant
l’´equation suivante et d´eterminer quand il est n´ecessaire
d’arrˆeter le processus :
E = Σ(ui,dj ,ri,j )∈T ei,j =
Σ(ui,dj ,ri,j )∈T (rij − ΣK
k=1pi,kqk,j)2
O`u T repr´esente l’ensemble de tuples observ´e de la forme
(ui, dj, ri,j), qui repr´esentent respectivement l’utilisateur
i, l’item j, la note attribu´e par i `a j.
6.2.3. R´EGULARISATION
Afin d’´eviter le ph´enom`ene de sur-apprentissage, nous
ajoutons un terme de r´egularisation `a la fonction de coˆut
comme suit :
e2
i,j = (rij − ΣK
k=1pi,kqk,j)2
+ β
2 ΣK
k=1( P 2
+ Q 2
)
Le param`etre β est utilis´e afin de contrˆoler les magnitudes
des vecteurs de caract´eristiques des utilisateurs et des items
( user-feature et item-feature) de telle mani`ere que Q et
P donnent une meilleure approximation de R sans avoir `a
contenir de grands nombres.
De la mˆeme mani`ere, nous obtenons les nouvelles r`egles de
mise `a jours :
pi,k = pi,k + α d
dpi,k
e2
ij = pi,k + α(2eijqk,j − βpi,k)
qk,j = qk,j + α d
dqk,j
e2
ij = qk,j + α(2eijpi,k − βqk,j)
Dans notre cas, nous avons choisi les valeurs de α et de β
par validation crois´ee (voir la section suivante).
7. Exp´erimentations
Nous avons commenc´e nos exp´erimentations par deviser
l’ensemble des donn´ees en deux sous ensembles apprentis-
sage et tests. Pour cela, nous avons introduit une variable](https://image.slidesharecdn.com/qgnduxzsro2wdk67motr-signature-e43c35fa3f0960967d3d76643ab96bbdf6c36b7e6d013c95e51290d1174e0c6b-poli-171205110954/85/Movie-Recommendation-system-7-320.jpg)
![770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
Movie Recommendation system
x qui d´etermine le pourcentage de donn´ees utilis´ees pour
l’apprentissage et pour les tests. Une valeur x = 0.8 in-
dique 80% des donn´ees d’apprentissage et 20% de tests.
L’ensemble des donn´ees contenant 4000056 instances a ´et´e
converti en une matrice A de la forme utilisateur-item ayant
12022 lignes (utilisateurs) et 17241 colonnes (films qui ont
´et´e not´e par au moins un utilisateur).
Pour nos exp´erimentation, nous avons aussi pris en con-
sid´eration un facteur qui est le niveau de parcimonie de la
base de donn´ees. Pour une matrice de donn´ees A, ce facteur
est d´efini par :
Niveau parcimonie = 1 − entree−non−nulles
totalite−d entrees
Dans notre cas, le niveau de parcimonie est ´egale `a :
Niveau parcimonie = 1 − 4000056
12022x17241 = 0, 9807
Avant de commencer l’´evaluation exp´erimentale compl`ete
des diff´erents algorithmes, nous d´eterminons la sensi-
bilit´e des diff´erents param`etres pour les diff´erentes ap-
proches. Ces param`etres incluent le step-size α , le taux
de r´egularisation β ainsi que le ratio d’apprentissage/test x.
Nous d´eterminons par la suite l’ensemble des valeurs opti-
males `a partir des graphes obtenus.
Afin de d´eterminer la sensibilit´e des param`etres, nous tra-
vaillons seulement sur l’ensemble d’apprentissage en le
subdivisant encore en deux sous ensembles (apprentis-
sage et tests) et effectuons nos exp´erimentations sur ces
derniers. Ainsi, nous avons effectu´e une cross-validation
en 5 folds, en choisissant al´eatoirement diff´erents ensem-
bles d’apprentissage et de test.
7.1. Environnement de d´eveloppement
l’ensemble de nos algorithmes ont ´et´e impl´ement´es
sous python en utilisant les librairies NUMPY et
GRAPHLAB[7]. Nous avons effectu´e toutes nos
exp´eriences sur machine ayant une processeur intel i7 `a 2.4
Ghz et ayant 8gb de m´emoire.
7.2. Mesure de performance
Il existe plusieurs mesures de performances utilis´ees dans
le domaine des syst`emes de recommandation. Ces mesures
peuvent ˆetre divis´ees en deux cat´egories :
7.2.1. DECISION SUPPORT
Ce type de mesures permet d’´evaluer `a quel point le
syst`eme de pr´ediction est efficace et `a quel point celui-ci
permet d’effectuer un choix coh´erent d’items `a proposer
aux utilisateurs. Cette mesure suppose que le processus de
pr´ediction est une op´eration binaire : soit les items sont cor-
rectement pr´edits (i.e. bons) ou non (i.e. mauvais). Avec
cette observation, Un item ayant un score de pr´ediction de
1,5 ou 2,5 sur 5 est sans importance si l’utilisateur choisit
de consid´erer que les pr´ediction de 4 ou plus. Les m´ethodes
les plus utilis´ees sont reversal rate et ROC sensitivity.
7.2.2. MESURE STATISTIQUE
Cette mesure de pr´ecision Permet d’´evaluer la pr´ecision
d’un syst`eme en comparant les notes pr´edites avec les notes
r´eelles attribu´ees par les utilisateurs. La mesure Root Mean
Squared Error RMSE est parmi les plus utilis´ees, une pe-
tite valeur de RMSE indique un syst`eme plus pr´ecis. Dans
notre cas, nous avons modifi´e cette mesure en ajoutant un
terme r´egularisation afin d’´eviter le sur-apprentissage et fa-
voriser le mod`ele le moins complexe.
7.3. R´esultats
Dans cette section nous pr´esentons non r´esultats
d’exp´erimentations de nos syst`emes de pr´ediction
collaborative bas´ee m´emoire (dans notre cas item-item
based) et bas´ee mod`ele (factorisation matricielle). Nous
commenc¸ons tout d’abord par comparer l’effet de
l’utilisation des diff´erents mesures de similarit´es dans la
premi`ere approche (item-item). Par la suite, nous utilis-
erons la meilleure mesure afin de comparer l’approche
collaborative bas´ee m´emoire et notre baseline. Dans
la derni`ere partie nous d´eterminons la sensibilit´e des
diff´erents param`etres de l’approche bas´ee mod`ele (fac-
torisation matricielle) en effectuant une cross-validation.
Ainsi, en fixant les param`etres nous comparons les
m´ethodes impl´ement´ees avec la baseline en terme de
pr´ecision. La mesure de pr´ecision utilis´ee `a travers les
exp´erimentation est RMSE avec un terme de r´egularisation.
7.4. Effets d’algorithmes de similarit´e
Nous avons impl´ement´e trois algorithmes de similarit´e
diff´erents qui sont : cosinus, la version am´elior´ee de Pear-
son Correlation Coefficient (permettant un calcule moins
couteux en terme de temps d’ex´ecution) et la distance eucli-
dienne. Les r´esultats sont repr´esent´es dans l’histogramme
suivant:](https://image.slidesharecdn.com/qgnduxzsro2wdk67motr-signature-e43c35fa3f0960967d3d76643ab96bbdf6c36b7e6d013c95e51290d1174e0c6b-poli-171205110954/85/Movie-Recommendation-system-8-320.jpg)
![990
991
992
993
994
995
996
997
998
999
1000
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
1011
1012
1013
1014
1015
1016
1017
1018
1019
1020
1021
1022
1023
1024
1025
1026
1027
1028
1029
1030
1031
1032
1033
1034
1035
1036
1037
1038
1039
1040
1041
1042
1043
1044
1045
1046
1047
1048
1049
1050
1051
1052
1053
1054
1055
1056
1057
1058
1059
1060
1061
1062
1063
1064
1065
1066
1067
1068
1069
1070
1071
1072
1073
1074
1075
1076
1077
1078
1079
1080
1081
1082
1083
1084
1085
1086
1087
1088
1089
1090
1091
1092
1093
1094
1095
1096
1097
1098
1099
Movie Recommendation system
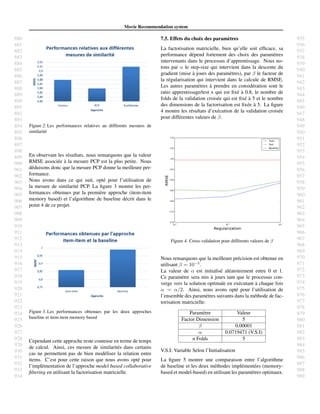
Figure 5. Les performances obtenues par les deux approches
baseline et item-item memory based
8. Conclusion
Les syst`emes de recommandation ont pour origines une
vari´et´e de domaines de recherche, tel que la recherche
d’information, le filtrage de l’information. Ils repr´esentent
une mani`ere innovante et puissante d’extraire des valeurs
partir de bases de donn´ees utilisateur. Ces syst`emes
aident les utilisateurs `a trouver les articles qu’ils souhait-
ent acheter. En effet, ces syst`emes font ainsi b´en´eficier
les utilisateurs en leur permettant de trouver les articles
qu’ils aiment. Tout en aidant ´egalement l’entreprise en
g´en´erant plus de ventes. Les syst`emes de recommanda-
tion sont en train de devenir un outil essentiel dans le com-
merce ´electronique sur le Web. Cependant, ces syst`emes
souffrent de l’´enorme volume de donn´ees utilisateur con-
tenu les bases de donn´ees existantes. Ces derniers en souf-
friront d’avantage ´etant donn´e la croissance du volume de
donn´ees utilisateur disponibles sur le Web qui est `a pr´evoir.
C’est pour cette raison que de nouvelles m´ethodes ont ´et´e
introduites afin de permettre d’am´eliorer consid´erablement
l’´evolutivit´e de ces syst`emes.
Dans ce projet, nous avons impl´ement´e diff´erentes
mani`eres de pr´edire `a quel point un utilisateur risque
d’appr´ecier un article. Nous avons ´egalement pr´esent´e
nos exp´erimentations et la mani`ere dont nous avons ´evalu´e
chaque algorithme mod´elisant un syst`eme de recomman-
dation. Les r´esultats obtenus montrent que les techniques
(memory-based) bas´ees sur le calcul de similarit´e bien
qu’elles soient efficaces restent couteuses en terme de
temps de calcul. Ainsi, leurs efficacit´e est relative `a la
mesure de similarit´e utilis´ee. Les m´ethodes (model-based)
quand `a elles, sont beaucoup moins couteuses en temps
d’ex´ecution et cela est du `a la factorisation matricielle.
Nous avons montr´e comment palier au ph´enom`ene de sur-
apprentissage en ajoutant un terme r´egularisation `a la fonc-
tion loss. Ainsi, la cross-validation nous a permet de choisir
les param`etres optimaux pour le syst`eme.
R´ef´erences
[1] Gediminas Adomavicius and Alexander Tuzhilin
”Toward the Next Generation of Recommender Systems:
A Survey of the State-of-the-Art and Possible Extensions”
IEEE Transactions on Knowledge, Vol 17, No 6, June 2005
[2] Dan R. Greening ”Building Consumer Trust with
Accurate Product Recommendations”, A White Paper on
LikeMinds Personalization Server
[3] D. Billsus and M. J. Pazzani, “Learning collabora-
tive information filters,” in AAAI 2008 Workshop on Rec-
ommender Systems, 1998.
[4] S. Funk, “Netflix update: Try this at home,”
http://sifter.org/˜ simon/journal/20061211.html, Archived
by WebCite at http://www. webcitation.org/5pVQphxrD,
December 2006.
[5] Royi Ronen, Noam Koenigstein, Elad Ziklik, Mikael
Sitruk, Ronen Yaari, Neta Haiby-Weiss, “Sage: Recom-
mender Engine as a Cloud Service,” Published in ACM
RecSys’13, Hong Kong, China, ACM 978- 1-4503-2409-
0/13/10, c ACM, October 12–16, 2013.
[6] GraphLab API, a DAT OT M machine learning
toolkit that provides users with state-of-theart algorithms
for classification. Version 1.8.0 https ://dato.com/
[7] David Goldberg, David Nichols, Brian M. Oki and
Douglas Terry, “Using Collaborative Filtering to Weave an
Information Tapestry,” Communications of the ACM, Vol.
35, No.12, December 1992.
[8] Yehuda Koren, “Matrix Factorization Techniques for
Recommender Systems,” Published by the IEEE Computer
Society, IEEE 0018-9162/09, pp. 42- 49, c IEEE, August
2009.
[9] Ruslan Salakhutdinov and Andriy Mnih, “Proba-
bilistic Matrix Factorization,” Published in the Proceed-
ings of Neural Information Processing Systems Foundation
(NIPS’07), December 4, 2007.](https://image.slidesharecdn.com/qgnduxzsro2wdk67motr-signature-e43c35fa3f0960967d3d76643ab96bbdf6c36b7e6d013c95e51290d1174e0c6b-poli-171205110954/85/Movie-Recommendation-system-10-320.jpg)



























