Téléchargé 1 138 fois



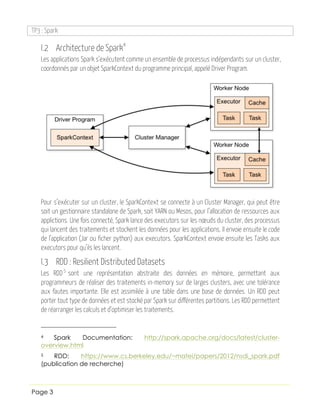
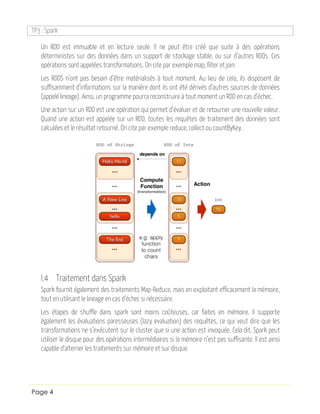



Le document présente Apache Spark comme une solution pour surpasser les limitations de Hadoop MapReduce, particulièrement pour les applications nécessitant des traitements à faible latence. Spark permet des traitements complexes via des graphes orientés acycliques et maintient les données en mémoire, optimisant ainsi les performances. Le TP inclut des exemples pratiques, comme le renommé 'Word Count', et propose une comparaison des performances entre MapReduce et Spark.


















































































