Télécharger pour lire hors ligne


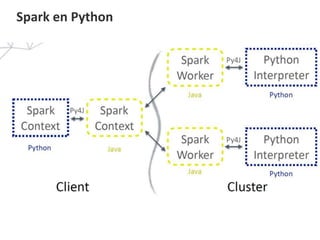
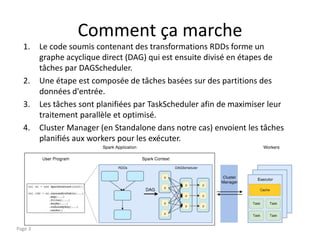

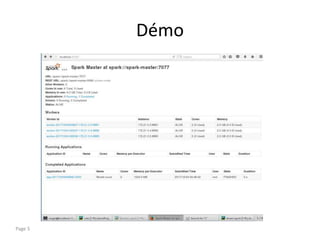

Le document présente les concepts clés d'Apache Spark, notamment les RDD qui sont des ensembles de données distribués résilients. Il explique le fonctionnement des transformations et des actions dans le traitement des données à l'aide d'un DAG et décrit l'architecture d'un cluster Spark incluant un master, un driver et plusieurs workers. Enfin, il mentionne les bibliothèques nécessaires et les méthodes de déploiement en mode standalone avec Docker.














































