Ce document présente une initiation à Apache Spark avec Java, en abordant les concepts fondamentaux, la mise en œuvre des RDDs (Resilient Distributed Datasets) et les opérations disponibles. Apache Spark est décrit comme un moteur de calcul distribué évoluant vers une alternative à Hadoop, intégrant plusieurs langages de programmation et nécessitant un environnement spécifique pour son installation. Les transformations et actions sur les RDDs sont également expliquées pour illustrer leur manipulation et l'évaluation des données.





![Spark Context
SparkContext est la couche d’abstraction qui permet `a Spark de savoir o`u
il va s’ex´ecuter.
Un SparkContext standard sans param`etres correspond `a l’ex´ecution en
local sur 1 CPU du code Spark qui va l’utiliser.
public class FirstRDD {
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext();
JavaRDD<String> lines = sc.textFile(”/path/fst.
txt”);}}
7/16](https://image.slidesharecdn.com/spark-170524105317/85/Introduction-Apche-Spark-7-320.jpg)
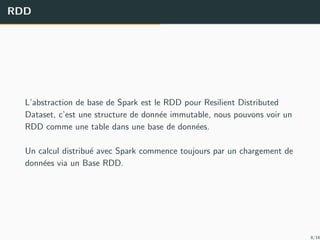


![Mise en oeuvre des RDDs
Les op´erations disponibles sur un RDD sont :
La cr´eation :
public class FirstRDD {
public static void main(String[] args) {
JavaRDD<String> lines = sc.textFile(”data.txt”);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);}}
13/16](https://image.slidesharecdn.com/spark-170524105317/85/Introduction-Apche-Spark-13-320.jpg)
![Mise en oeuvre des RDDs
Les transformations :
Les transformations ne retournent pas de valeur seule, elles retournent un
nouveau RDD. Par exemple : map, filter, flatMap, groupByKey,
reduceByKey.
public class FirstRDD {
public static void main(String[] args) {
JavaRDD<String> lines = sc.textFile(”data.txt”);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);
JavaRDD<Integer> 2distData = distData.map(( i)−>{
return i∗2;});}}
14/16](https://image.slidesharecdn.com/spark-170524105317/85/Introduction-Apche-Spark-14-320.jpg)
![Mise en oeuvre des RDDs
L’action :
Les actions ´evaluent et retournent une nouvelle valeur. Au moment o`u
une fonction d’action est appel´ee sur un objet RDD, toutes les requˆetes
de traitement des donn´ees sont calcul´ees et le r´esultat est retourn´e. Les
actions sont par exemple reduce, collect, count, first, take, countByKey
et foreach.
public class FirstRDD {
public static void main(String[] args) {
JavaRDD<String> lines = sc.textFile(”data.txt”);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);
JavaRDD<Integer> = distData.reduce((j,i) −> {
return i + j;});}}
15/16](https://image.slidesharecdn.com/spark-170524105317/85/Introduction-Apche-Spark-15-320.jpg)
![Les Pairs RDD
Spark offre des fonctionnalit´es sp´ecifiques aux RDD clef-valeur,
RDD[(K,V)] . Il s’agit notamment des fonctions groupByKey,
reduceByKey, mapValues, countByKey, cogroup.
JavaRDD<String> lines = sc.textFile(”data.txt”);
JavaPairRDD<String, Integer> pairs;
pairs = lines.mapToPair(s −> new Tuple2(s, 1));
JavaPairRDD<String, Integer> counts;
counts = pairs.reduceByKey((a, b) −> a + b);
16/16](https://image.slidesharecdn.com/spark-170524105317/85/Introduction-Apche-Spark-16-320.jpg)

































