Téléchargé 115 fois



















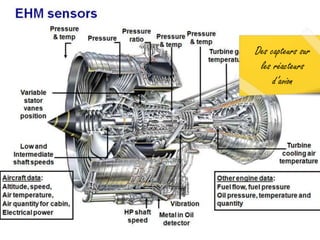


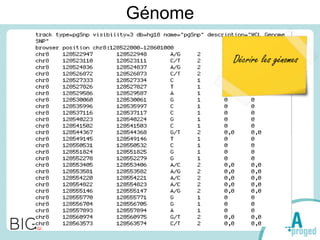






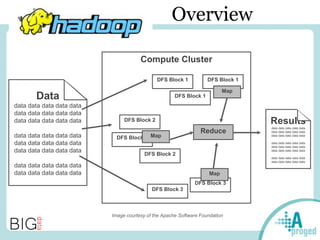

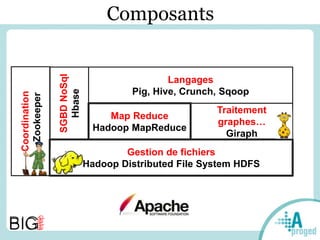

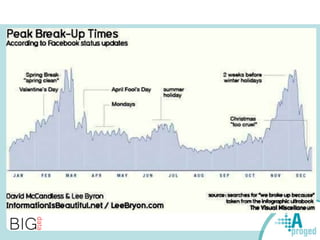

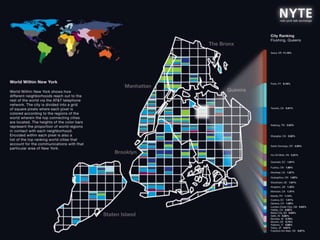
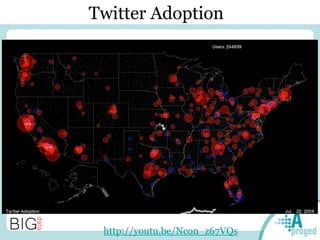


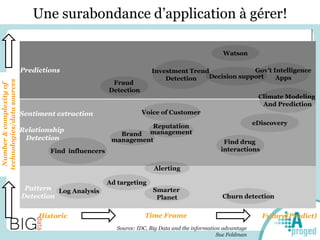



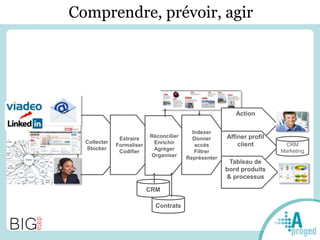

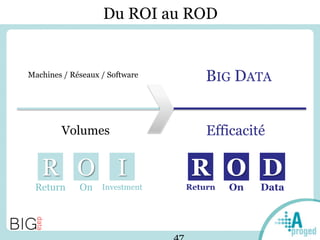

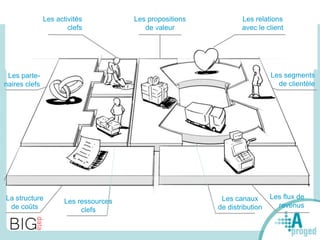






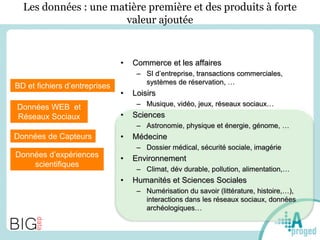










Le document traite du Big Data et de son impact sur la gestion des données numériques, soulignant le rôle essentiel de l'APROGED dans la réflexion sur l'optimisation de ces contenus. Il évoque également les défis liés au stockage, à l'analyse complexe et à la visualisation des grandes quantités de données, tout en présentant divers cas d'utilisation et segments de clientèle. Enfin, il aborde les enjeux juridiques et la nécessité d'une formation adaptée pour les professionnels du secteur.























































































