Télécharger en tant que PPSX, PPTX











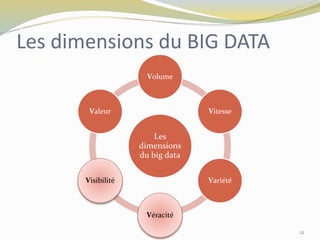















Le document traite des big data, définitions, origines et catégories, en soulignant leur volume, vitesse, variété et valeur. Il explore les sources de production de données, telles que les applications professionnelles, le web, les médias sociaux et l'internet des objets, ainsi que les défis technologiques liés à leur gestion. En outre, il souligne l'importance de la visualisation des données pour la prise de décision dans les entreprises.








































































![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)



