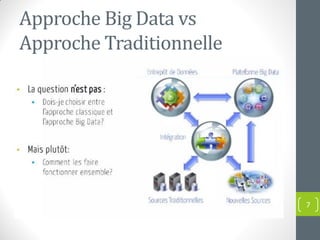
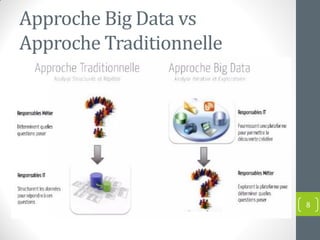
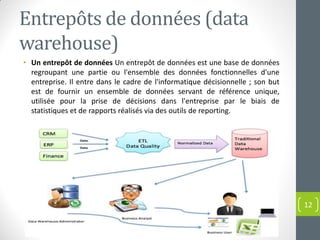
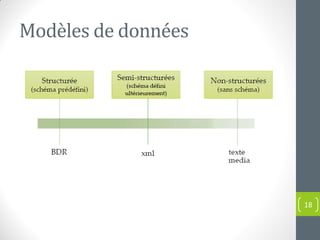
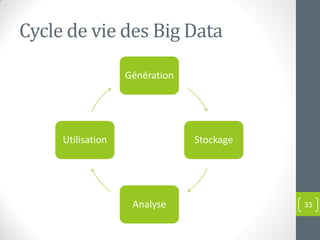
Le document présente une introduction au concept de big data, incluant sa définition, ses caractéristiques (volume, variété, vélocité, véracité, valeur) et ses applications dans divers domaines. Il met en évidence les défis et les approches traditionnelles face aux volumes massifs de données, soulignant l'importance de nouvelles technologies et compétences. Enfin, il aborde les implications pour les entreprises et les opportunités offertes par l'analyse des données à grande échelle.