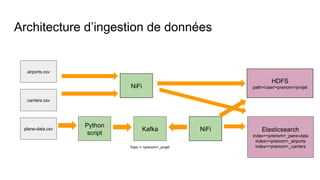
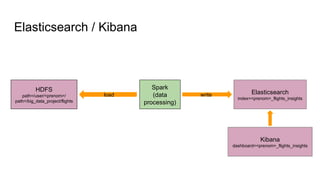
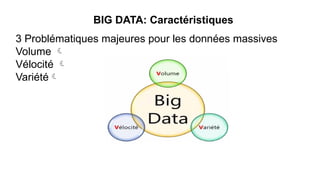
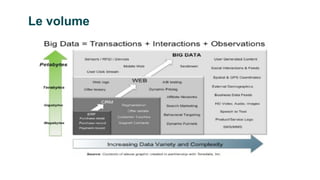
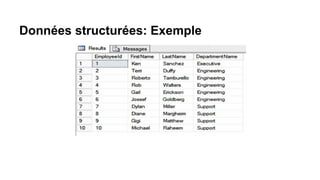
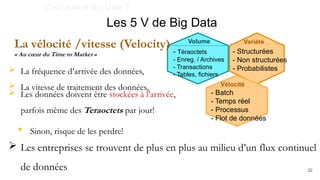
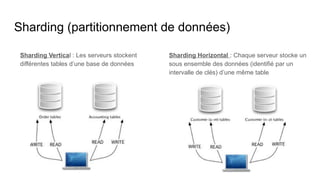
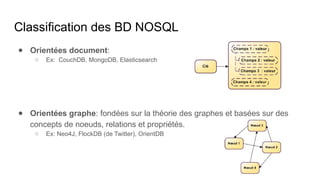
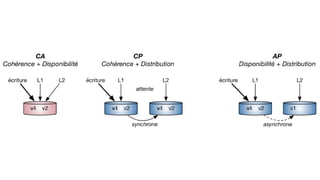
Le document présente un plan de cours sur le big data, couvrant des sujets tels que les bases de données NoSQL, Hadoop, et les traitements de données avec des outils comme Apache Spark et Elasticsearch. Il inclut également un projet pratique utilisant des ensembles de données d'aéroports et des analyses spécifiques à réaliser via des scripts en Python et des requêtes HiveQL. Enfin, il aborde les caractéristiques fondamentales du big data, notamment le volume, la vélocité et la variété des données.