






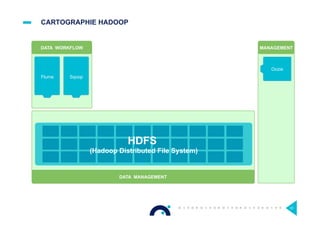
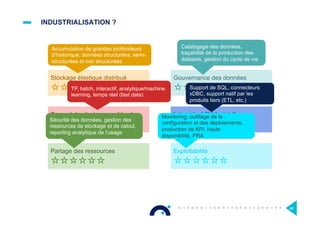
![HADOOP : DES DISTRIBUTIONS [1/2]
¤ Pourquoi une distribution ?
> Une installation pour avoir la plupart des outils d’Hadoop
> Combinaison de versions compatibles
14](https://image.slidesharecdn.com/afterwork-hadoop-1-160610081352/85/Afterwork-hadoop-14-320.jpg)
![HADOOP : DES DISTRIBUTIONS [1/2]
¤ Pourquoi une distribution ?
> Une installation pour avoir la plupart des outils d’Hadoop
> Combinaison de versions compatibles
> Upgrade
> Support éditeur
¤ Trois distributeurs majeurs :
> HortonWorks
> Cloudera
> MapR
¤ Les éditeurs traditionnels sont des suiveurs sur Hadoop
> Teradata, Oracle, Microsoft, IBM, etc.
> Certains s’appuient sur une des 3 distributions majeures
17](https://image.slidesharecdn.com/afterwork-hadoop-1-160610081352/85/Afterwork-hadoop-17-320.jpg)
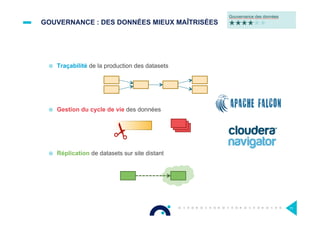
![HADOOP : DES DISTRIBUTIONS [2/2]
18
400 KLOC
200 KLOC
0](https://image.slidesharecdn.com/afterwork-hadoop-1-160610081352/85/Afterwork-hadoop-18-320.jpg)








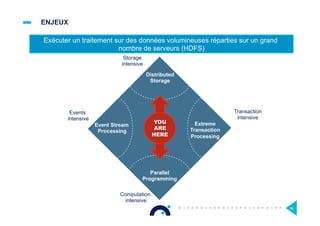
![DÉPASSER MAPREDUCE [1/4]
¤ MapReduce, le modèle de programmation à l’origine d’Hadoop, s’avère
contraignant et sous-optimisé pour certains types de traitements
Map Reduce
Map Reduce
Map Reduce
Traitement unique
4 phases d’I/O
Traitement itératif
N x 4 phases d’I/O
39](https://image.slidesharecdn.com/afterwork-hadoop-1-160610081352/85/Afterwork-hadoop-39-320.jpg)
![DÉPASSER MAPREDUCE [2/4]
Dans le contexte d’Hadoop 1,
MapReduce joue le rôle de…
A: Algorithme distribué
B: Framework de dév.
C: Plateforme de distribuJon
D: La réponse D
40](https://image.slidesharecdn.com/afterwork-hadoop-1-160610081352/85/Afterwork-hadoop-40-320.jpg)
![DÉPASSER MAPREDUCE [2/4]
Dans le contexte d’Hadoop 1,
MapReduce joue le rôle de…
A: Algorithme distribué
B: Framework de dév.
C: Plateforme de distribuJon
D: La réponse D
41](https://image.slidesharecdn.com/afterwork-hadoop-1-160610081352/85/Afterwork-hadoop-41-320.jpg)
![DÉPASSER MAPREDUCE [3/4]
Hadoop 1.x
HDFS
(redundant, reliable storage)
MapReduce
(cluster resource management
& data processing)
Batch Apps
HDFS
(redundant, reliable storage)
YARN
(cluster resource management)
MapReduce
(data processing)
Others
(data processing)
Hadoop 2.x
Tez
(data processing)
Batch, Interactive, Streaming, etc.
42](https://image.slidesharecdn.com/afterwork-hadoop-1-160610081352/85/Afterwork-hadoop-42-320.jpg)
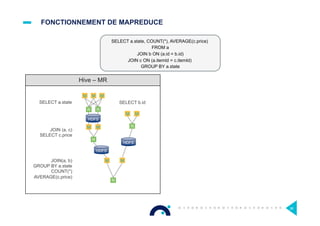
![DÉPASSER MAPREDUCE [4/4]
Fonctionnement de TEZ
Hive – MR
SELECT a.state
JOIN (a, c)
SELECT c.price
SELECT b.id
JOIN(a, b)
GROUP BY a.state
COUNT(*)
AVERAGE(c.price)
M M M
R R
M M
R
M M
R
M M
R
HDFS
HDFS
HDFS
SELECT a.state, COUNT(*), AVERAGE(c.price)
FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemId = c.itemId)
GROUP BY a.state
M MM
R R
R
M M
R
R
SELECT a.state,
c.itemId
JOIN (a, c)
JOIN(a, b)
GROUP BY a.state
COUNT(*)
AVERAGE(c.price)
SELECT b.id
Tez avoids
unnecessary writing to
HDFS
Hive – Tez
43](https://image.slidesharecdn.com/afterwork-hadoop-1-160610081352/85/Afterwork-hadoop-43-320.jpg)


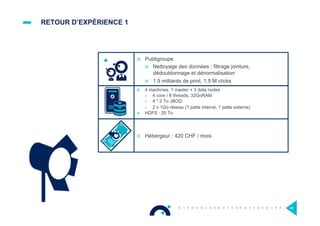
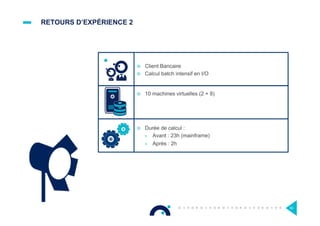

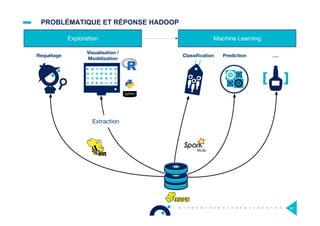
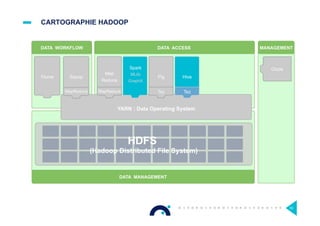

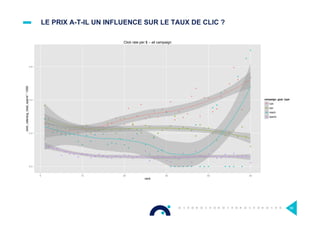

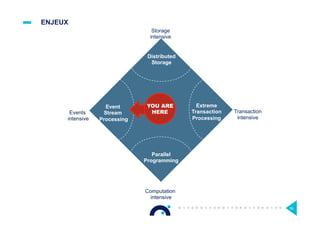
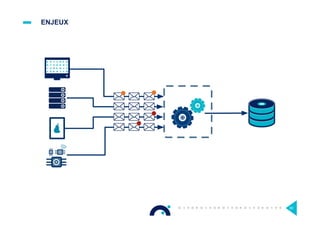
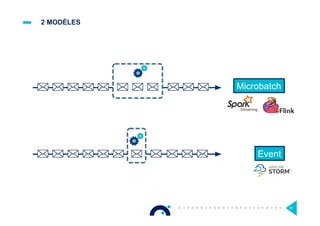
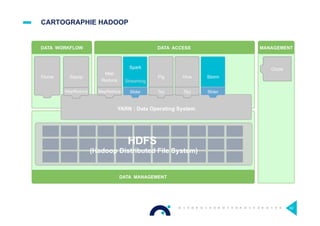
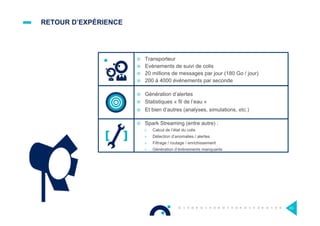
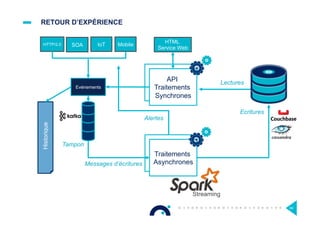
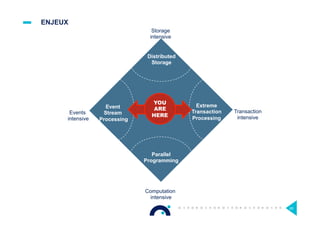
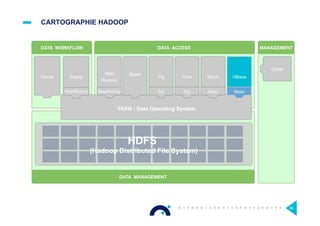




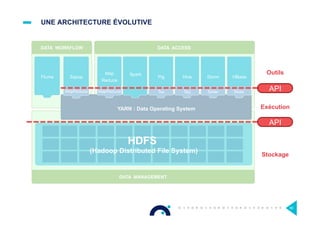




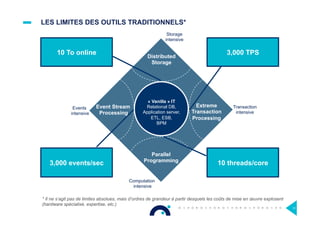
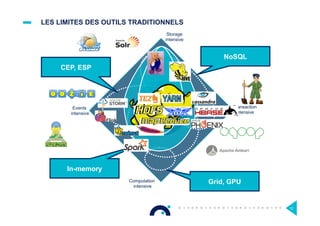
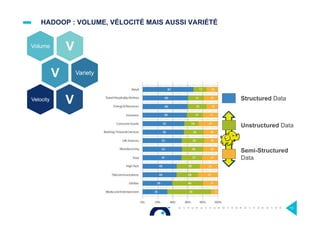
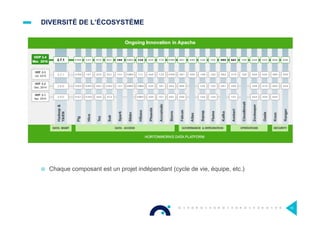
Le document présente l'impact et les chiffres clés des projets Big Data chez Octo, notamment les volumes de données traitées et l'infrastructure Hadoop mise en place. En outre, il aborde les défis et les limites des outils traditionnels par rapport à l'écosystème Hadoop, tout en mettant en avant des cas d'utilisation spécifiques dans différents secteurs. Enfin, le texte souligne les améliorations et la maturité croissante de Hadoop en 2016, notamment en termes de gouvernance des données et de sécurité.

















































































