Télécharger en tant que PDF, PPTX









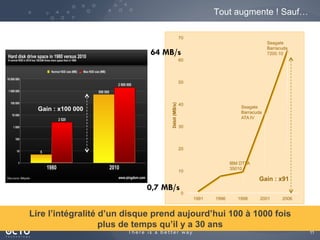




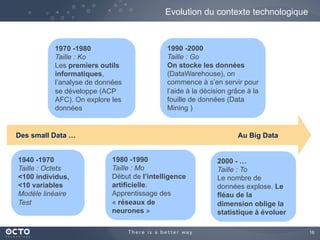

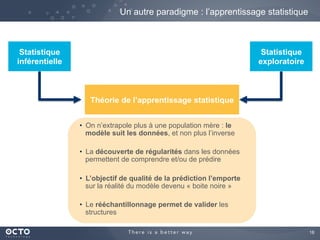
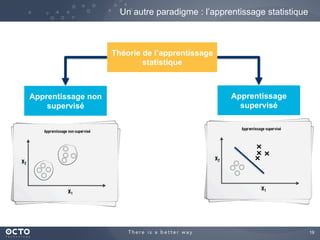
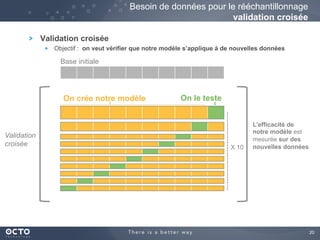
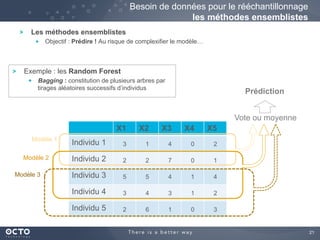
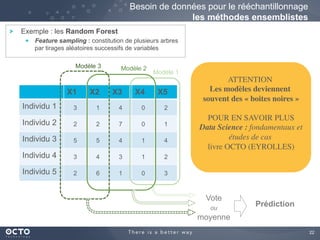
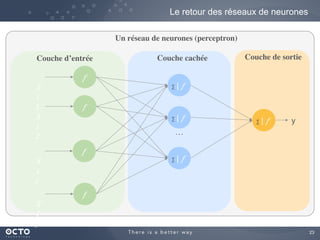
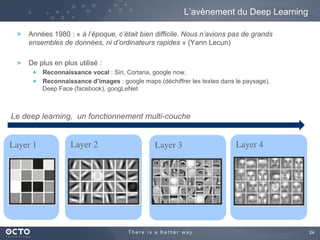




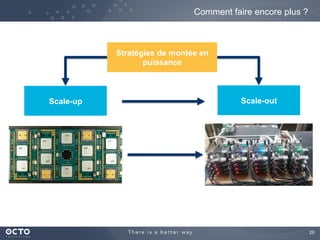
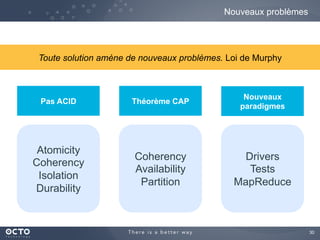
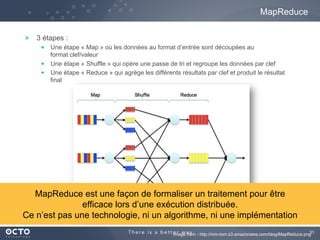
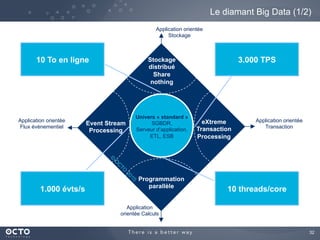
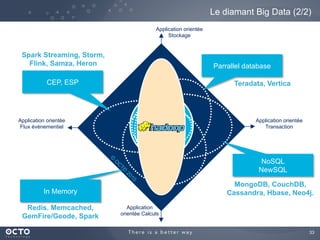


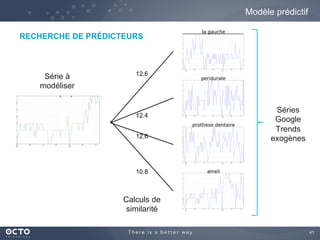
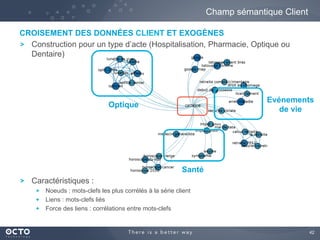
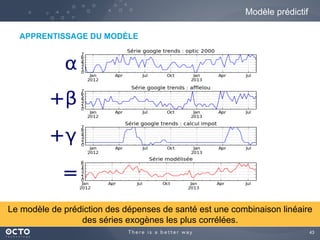
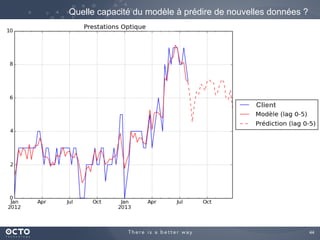
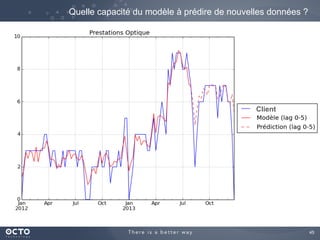

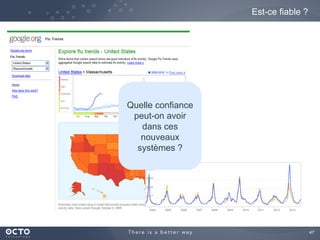
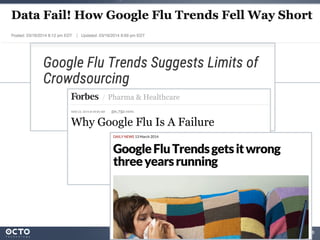







Le document traite de l'évolution des données, depuis les small data jusqu'aux big data, et de l'impact de cette transformation sur les méthodes de traitement et d'analyse des données. Il souligne le passage d'une statistique classique à des approches d'apprentissage statistique, ainsi que la nécessité d'adapter les outils technologiques pour gérer des volumes de données toujours plus importants. En conclusion, il met en avant l'importance des capacités d'apprentissage améliorées grâce à ces technologies pour avoir une meilleure compréhension et prédiction des phénomènes.







































































