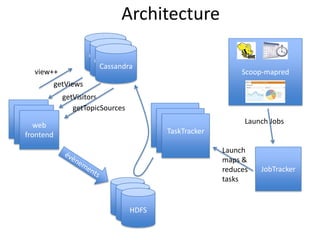
Le document traite de l'utilisation de Hive et Hadoop pour gérer des statistiques web, avec des exemples de compteur de vues et de visiteurs, ainsi que des méthodes de stockage des événements. Il compare également les performances de Cassandra et HBase, ainsi que celles de Hive et Pig pour l'analyse des données. Enfin, il évoque l'architecture, les besoins et les défis rencontrés lors de la mise en œuvre de ces technologies.






















![HDFS et les petits fichiers
$ sudo hadoop-fuse-dfs dfs://namenode:8020 ro hdfs
$ du -sh hdfs/events
78G hdfs/events
$ ls -l hdfs/events/GrabbedPostEvent/20121201/grabbing.10.tsv.gz
-rw-r--r-- 1 99 99 2,6M 2012-12-01 07:04 hdfs/events/GrabbedPo[...]
$ ls -l hdfs/events/PageViewEvent/20121201/web-3.6.tsv.gz
-rw-r--r-- 1 99 99 960K 2012-12-01 04:47 hdfs/events/PageViewE[...]
$ du -sh hdfs/apache_logs
360G hdfs/apache_logs](https://image.slidesharecdn.com/statswebscoopit-121214044639-phpapp02/85/Stats-web-avec-Hive-chez-Scoop-it-32-320.jpg)


































































