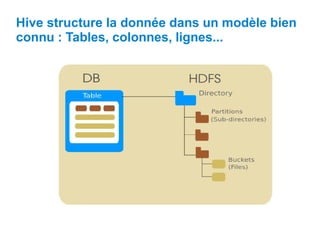
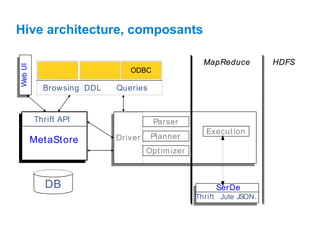
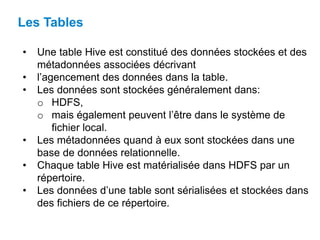
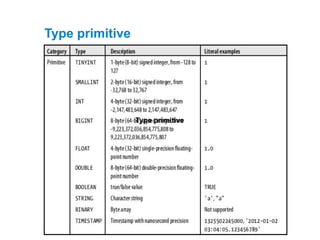
Ce document présente Hive, un entrepôt de données basé sur Hadoop, conçu pour faciliter la manipulation de grandes quantités de données au moyen de requêtes SQL. Il décrit son architecture, incluant des composants comme le metastore, le driver, et les opérations sur les tables, telles que la création, la gestion des partitions et des buckets. Hive permet de gérer des données stockées dans HDFS avec des métadonnées décrivant leurs agencements et supporte divers types de données, incluant des types primitives et complexes.


















![Hive - Create Database
CREATE DATABASE|SCHEMA [IF NOT EXISTS]
<database name>
Syntaxe
hive> CREATE DATABASE [IF NOT EXISTS] userdb;
Exemple
hive> CREATE SCHEMA userdb;
ou
hive> SHOW DATABASES;
default
userdb](https://image.slidesharecdn.com/prsentationhive-240516205257-b297c2ca/85/Presentation-langage-de-programmationHive-pdf-22-320.jpg)
![Hive - Drop Database
DROP DATABASE StatementDROP (DATABASE|SCHEMA)
[IF EXISTS] database_name;
Syntaxe
hive> DROP DATABASE IF EXISTS userdb;
Exemple
DROP SCHEMA userdb;
ou](https://image.slidesharecdn.com/prsentationhive-240516205257-b297c2ca/85/Presentation-langage-de-programmationHive-pdf-23-320.jpg)
![Hive - Create Table
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS]
[db_name.] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]
Syntaxe](https://image.slidesharecdn.com/prsentationhive-240516205257-b297c2ca/85/Presentation-langage-de-programmationHive-pdf-24-320.jpg)

![Load Data
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO
TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]
Syntaxe](https://image.slidesharecdn.com/prsentationhive-240516205257-b297c2ca/85/Presentation-langage-de-programmationHive-pdf-26-320.jpg)

![Hive - Alter Table
ALTER TABLE name RENAME TO new_name
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
ALTER TABLE name DROP [COLUMN] column_name
ALTER TABLE name CHANGE column_name new_name new_type
ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
Syntaxe
hive> ALTER TABLE employee RENAME TO emp;
Exemple
hive> ALTER TABLE employee CHANGE name ename String;
hive> ALTER TABLE employee CHANGE salary salary Double;
hive> ALTER TABLE employee ADD COLUMNS (
> dept STRING COMMENT 'Department name');](https://image.slidesharecdn.com/prsentationhive-240516205257-b297c2ca/85/Presentation-langage-de-programmationHive-pdf-28-320.jpg)

![Hive - DropTable
DROP TABLE [IF EXISTS] table_name;
Syntaxe
hive> DROP TABLE IF EXISTS employee;
Exemple
hive> SHOW TABLES;
emp
ok
Time taken: 2.1 seconds](https://image.slidesharecdn.com/prsentationhive-240516205257-b297c2ca/85/Presentation-langage-de-programmationHive-pdf-30-320.jpg)




















