Télécharger en tant que PDF, PPTX

































![CQL
CREATE TABLE members (
username text,
firstname text,
email list<text>,
PRIMARY KEY (username)
);
members
bob
firstname
...
Robert
...
...
bill
...
firstname
...
William
INSERT INTO members (username, firstname,
email)
VALUES ('bob', 'Robert',
['bob@gmail.com', 'bob@yahoo.fr']
);](https://image.slidesharecdn.com/cassandra-140304062409-phpapp02/85/Apache-Cassandra-Concepts-et-fonctionnalites-50-320.jpg)


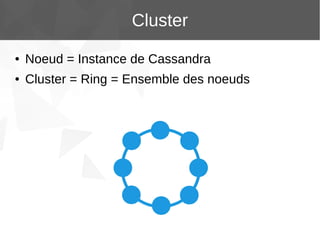
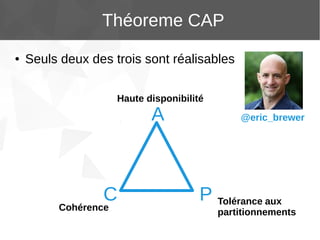
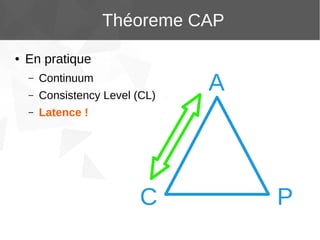
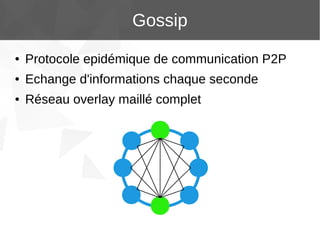
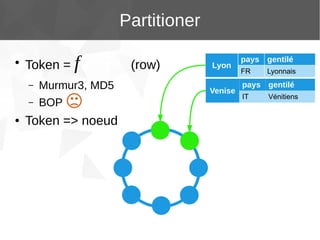
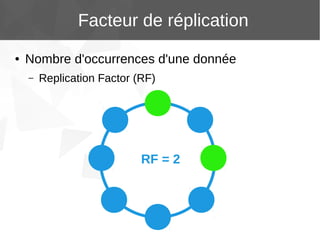
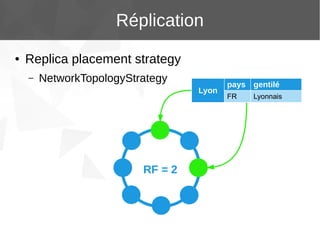
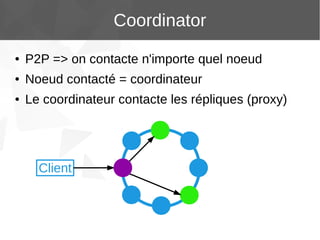
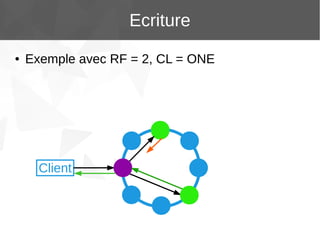
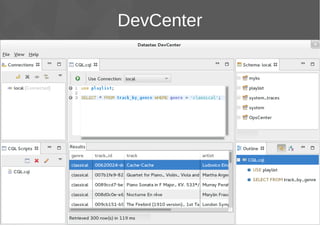
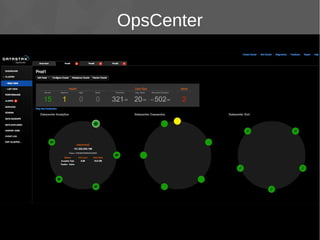
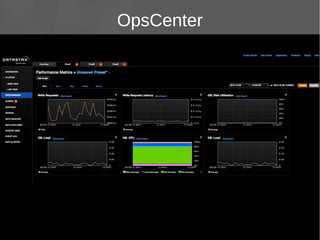
Le document présente Apache Cassandra, un système de gestion de base de données NoSQL orienté colonnes, distribué et hautement disponible. Il discute des concepts clés, de l'architecture, des fonctionnalités, des outils et du modèle de données de Cassandra. L'installation et l'utilisation de Cassandra, ainsi que ses avantages par rapport aux SGBDR traditionnels, sont également abordées.



































































