Télécharger en tant que PDF, PPTX







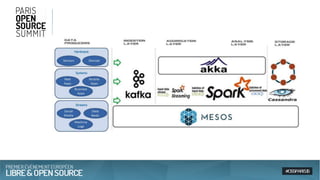


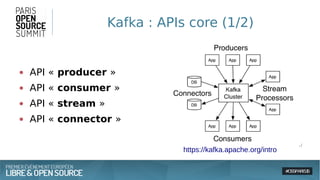























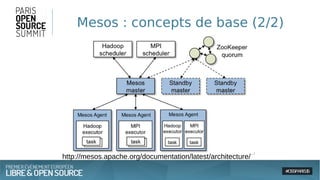





Le document présente une approche architecturale pour le traitement des données massives en utilisant des technologies open source comme Spark, Akka, Cassandra et Kafka. Il explore les défis du big data, les avantages de chaque outil et leur intégration pour un traitement en temps réel et une gestion efficace des systèmes distribués. Enfin, il souligne la scalabilité et la faible latence nécessaires pour des applications orientées données.









































![[若渴計畫2015.8.18] SMACK](https://cdn.slidesharecdn.com/ss_thumbnails/smack-150723041910-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

























