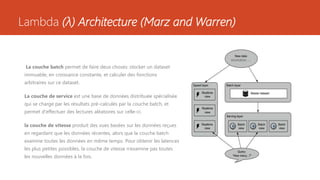
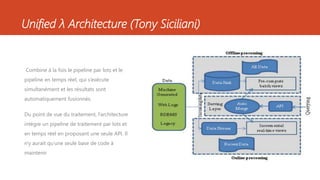
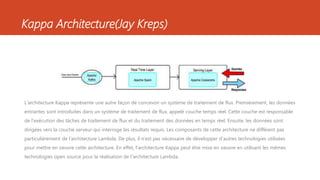
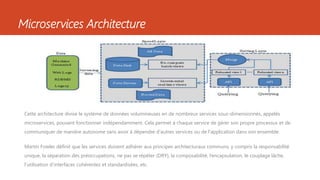
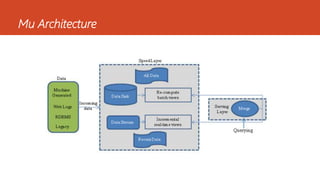
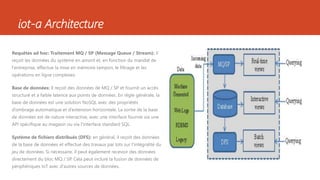
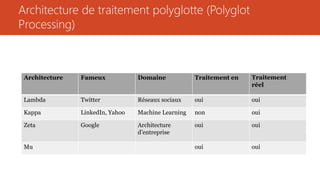
Ce document présente diverses architectures de big data, y compris les architectures lambda, kappa, unifiée, microservices, mu et zeta, chacune ayant ses propres caractéristiques et méthodologies de traitement des données. Il aborde également l'importance de ces architectures dans le traitement en temps réel et le stockage des données, et compare leurs avantages et inconvénients. En outre, le document évoque des architectures supplémentaires et fournit des ressources pour approfondir ces concepts.



















![[TNT19] Hands on: Objectif Top Architecte!](https://cdn.slidesharecdn.com/ss_thumbnails/objectiftoparchitectefinal-190201181915-190202084057-thumbnail.jpg?width=640&height=640&fit=bounds)



















