Téléchargé 58 fois





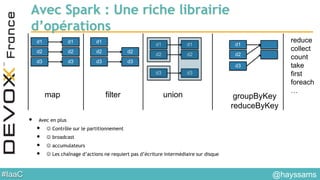



![#IaaC
Exemple de commande Marathon
POST /v2/apps HTTP/1.1
{
"id": "TomcatApp",
"cmd": "/path/bin/catalina.sh run $PORT",
"mem": 1024,
"cpus": 2.0,
"instances": 3,
"constraints": [
]
}
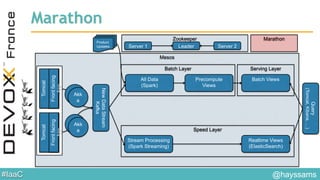
• Marathon utilisé pour lancer
• Kafka
• ElasticSearch
• Tomcat
• Scale up/down par simple appel REST avec une nouvelle configuration
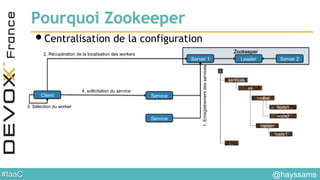
Régulation de charge et
découverte
GET /apps/MonApp/tasks
Hot haproxy.cfg reload
@hayssams
["hostname", "UNIQUE", ""],
["hostname", ”like", ”front{1,2}"]](https://image.slidesharecdn.com/devoxxfr2014-140424012027-phpapp01/85/Realtime-Web-avec-Kafka-Spark-et-Mesos-25-320.jpg)

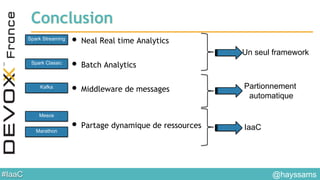


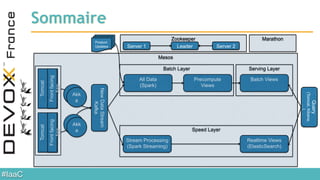
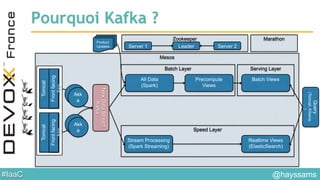
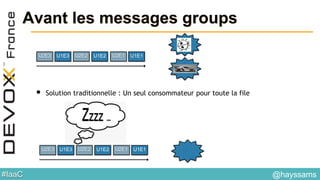
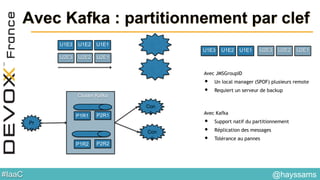
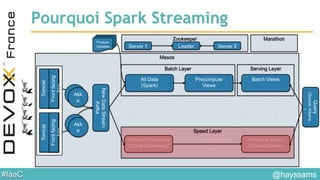
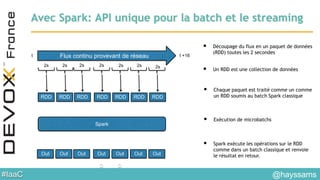
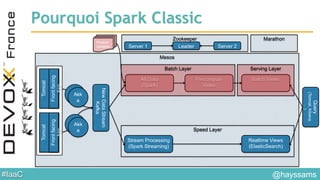
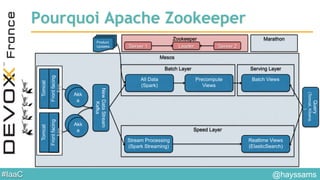
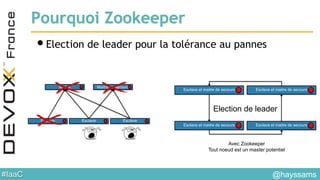
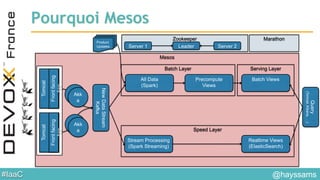
Le document aborde l'architecture d'un système en temps réel utilisant Kafka, Spark et Mesos pour le traitement de flux et l'analyse en temps réel. Il décrit les avantages du partitionnement et de la tolérance aux pannes de Kafka, ainsi que l'intégration de Spark pour le traitement continu des données. Enfin, il présente l'utilisation de Mesos et Marathon pour la gestion des ressources et le déploiement d'applications sur une infrastructure unifiée.



































































