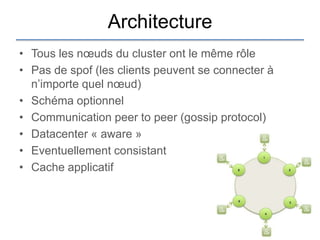
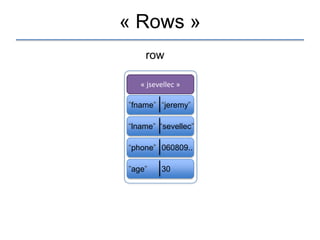
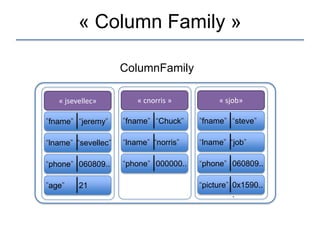
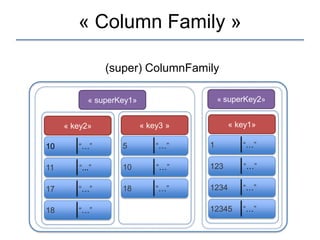
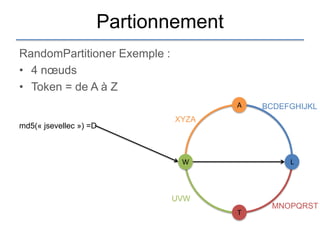
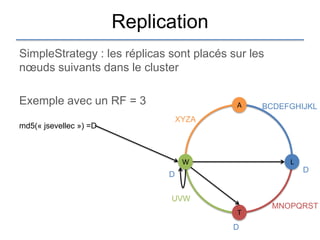
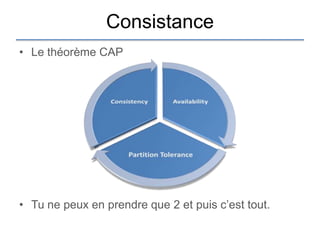
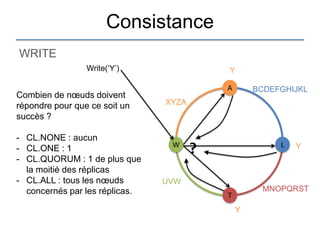
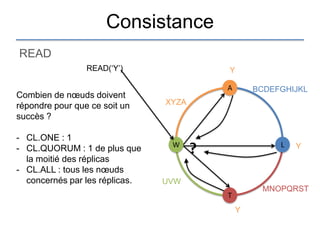
Le document présente une introduction à Cassandra, une base de données NoSQL développée par Facebook, qui est distribuée, hautement performante et scalable. Il aborde ses caractéristiques, telles que l'absence de point de défaillance unique, la gestion de la consistance, et les différentes architectures comparées aux bases de données relationnelles (RDBMS). Le document fournit également des informations sur l'utilisation de l'API Hector et des conseils pour développer des applications avec Cassandra.