Télécharger en tant que PDF, PPTX








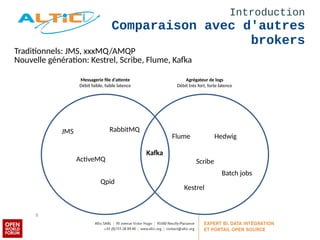










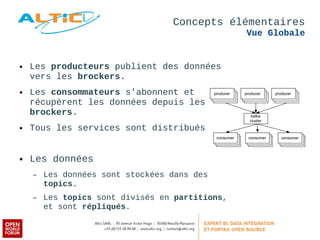
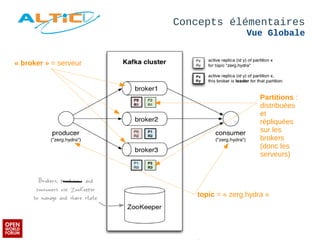
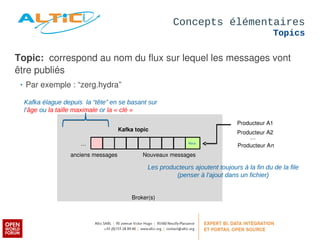
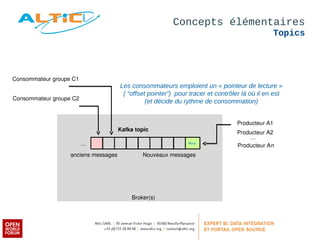
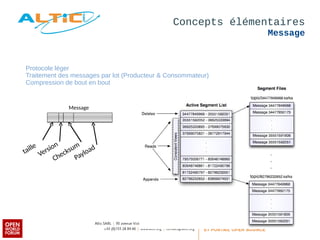
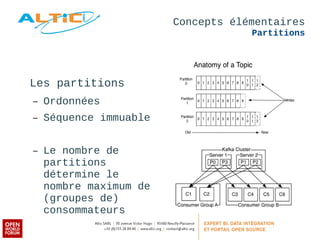
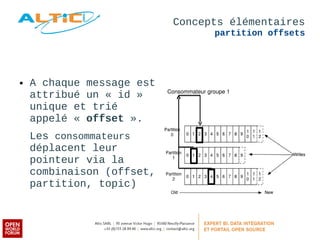


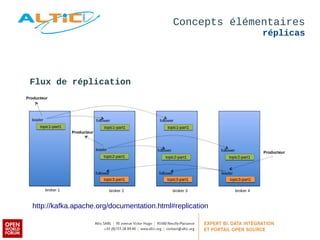
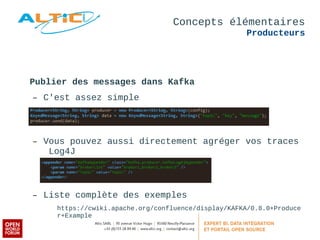






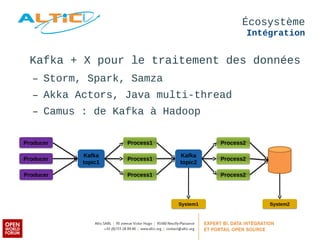





Apache Kafka est un système de messagerie distribué, rapide et tolérant aux pannes, principalement utilisé pour l'agrégation de logs et le traitement en temps réel. Développé à l'origine par LinkedIn, il permet aux producteurs de publier des messages dans des topics, qui sont ensuite consommés par des consommateurs, avec un modèle de réplication pour la durabilité des données. Avec des cas d'utilisation divers tels que Netflix et Spotify, Kafka est devenu un outil clé dans l'écosystème du big data et du streaming.






























































