Télécharger en tant que PDF, PPTX






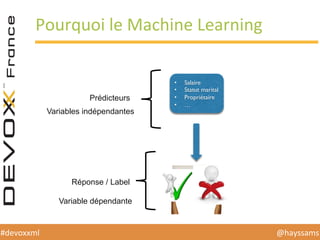
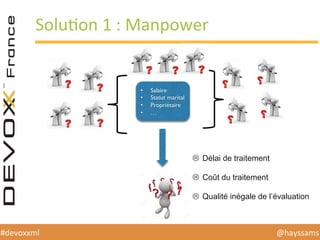
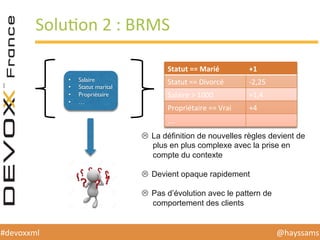
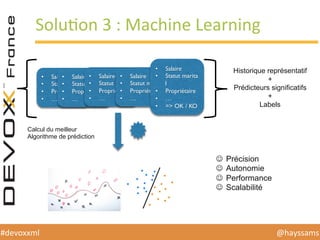





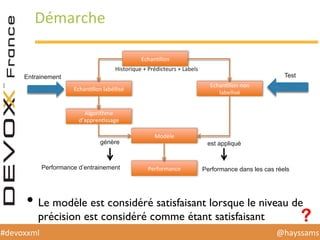
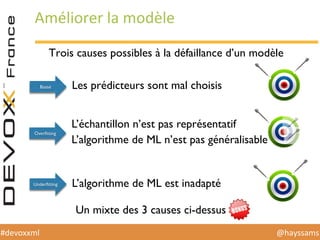
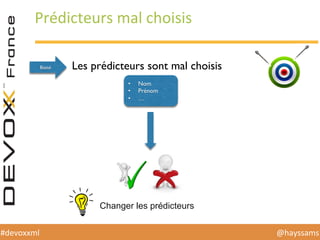
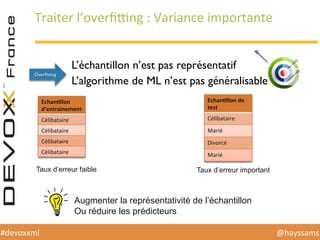
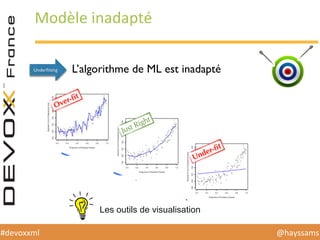








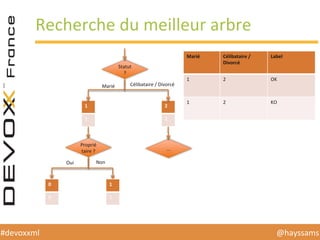
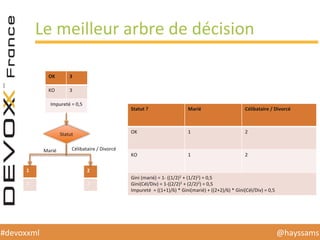











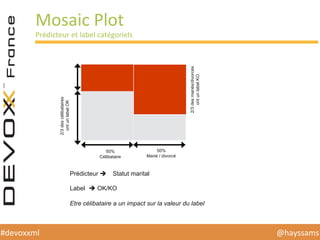

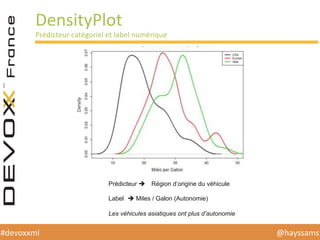
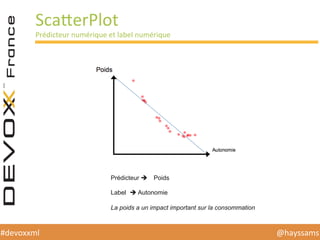



Le document présente une conférence sur l'apprentissage automatique utilisant Spark, MLlib et D3.js, soulignant l'importance de la préparation des données, de la sélection d'algorithmes et de la visualisation des résultats. Il expose divers concepts tels que la classification, la régression et le clustering, ainsi que des solutions aux défis rencontrés dans le processus d'apprentissage. La conclusion insiste sur la nécessité d'une bonne compréhension des prédicteurs et des labels pour tirer parti effective des techniques de machine learning.


























