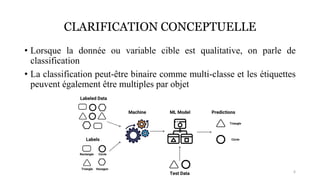
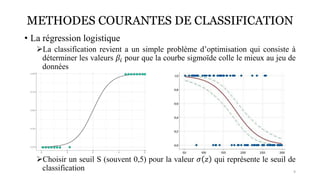
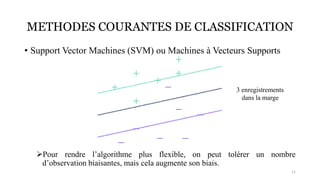
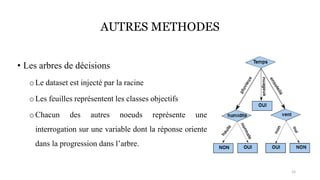
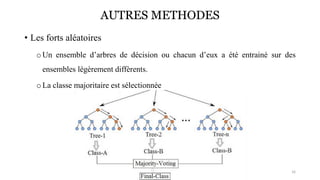
La classification est une méthode en Intelligence Artificielle qui consiste a ranger des élements dans différentes catégories prédéfinies sans intervention de l'humain, de maniere autonome. Ici, vous en saurez plus par rapport a ce type d'apprentissage supervisé (car nécéssite un entrainement de modele) et découvirez comment elle peut etre mis en place.













































![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)




