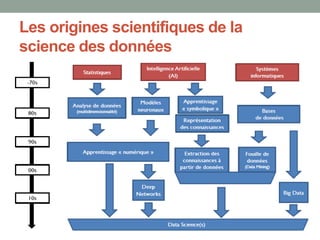
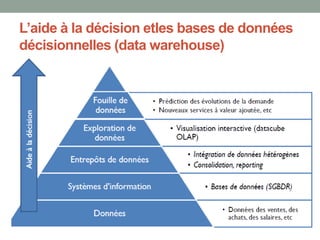
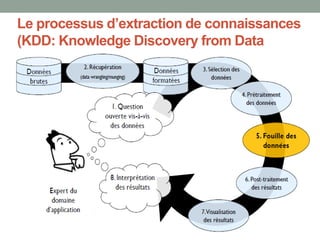
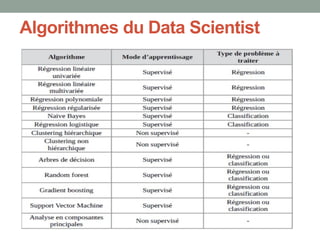
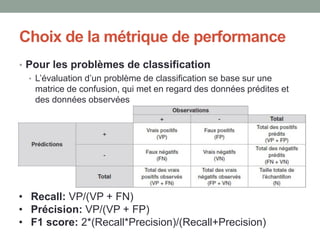
Le document présente une introduction à la science des données, abordant des concepts fondamentaux tels que le machine learning, les algorithmes supervisés et non supervisés, et des techniques de validation croisée. Il explique également la distinction entre régression et classification, ainsi que les méthodes d'évaluation des modèles, incluant la courbe ROC et les métriques de performance. Enfin, le texte traite des défis posés par les données de grande dimension et les valeurs manquantes, en proposant des solutions pour le traitement de ces défis.