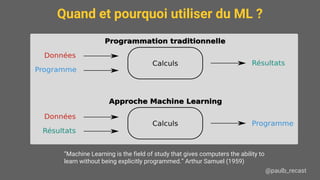
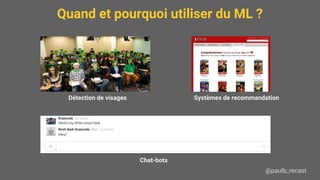
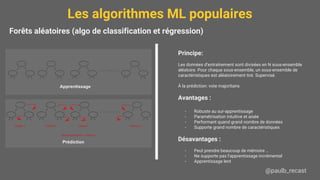
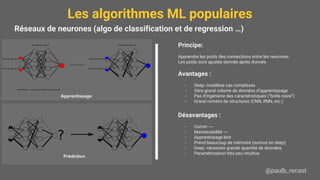
Le document présente une introduction au machine learning (ML), y compris ses applications, les types d'apprentissage et les algorithmes populaires comme les arbres de décision, la régression linéaire, et les réseaux de neurones. Il souligne l'importance de bien définir le problème à résoudre, de comprendre les données disponibles, et de prendre en compte les contraintes de mémoire et de vitesse. Enfin, des conseils pratiques sont donnés pour choisir l'algorithme approprié et pour évaluer les modèles.