Télécharger pour lire hors ligne



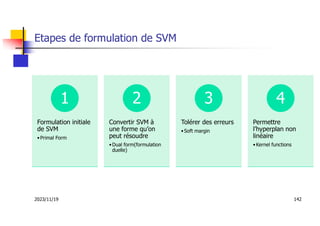



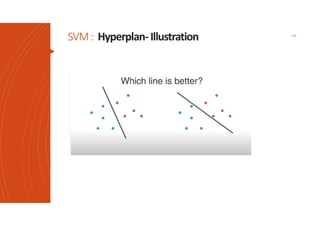
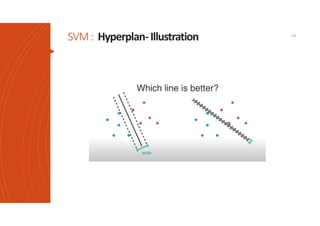
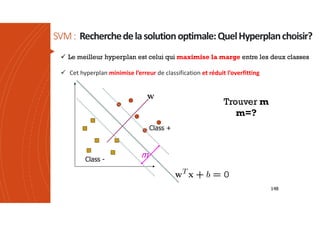
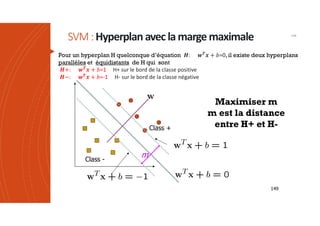
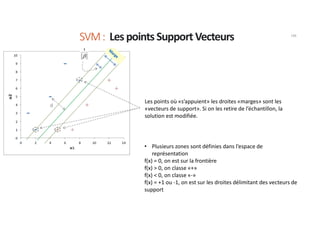
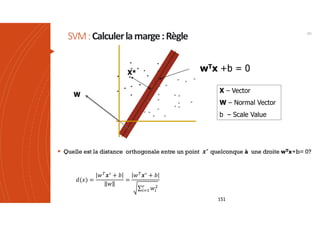
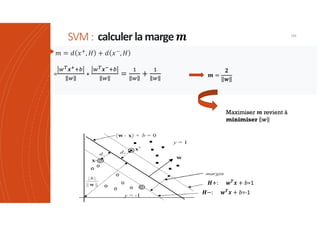







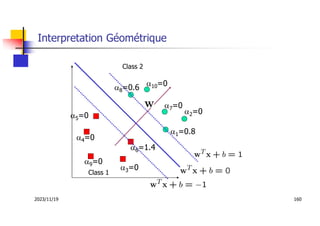


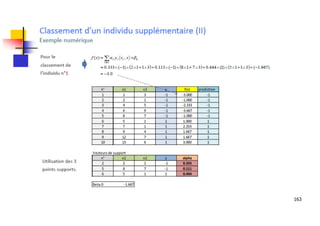







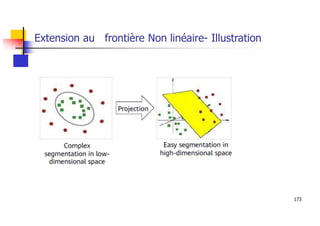






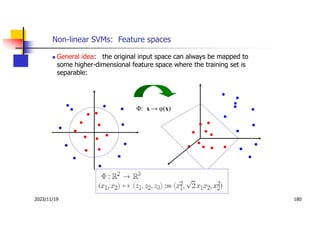


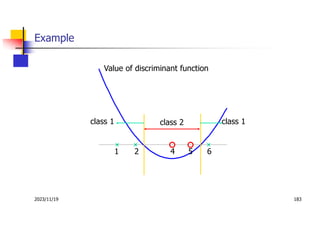






Les machines à vecteurs de support (SVM) sont des classifieurs linéaires développés pour séparer deux classes de données, avec une méthode permettant également la séparation non linéaire à l'aide de fonctions noyau. La formulation SVM repose sur l'optimisation d'un hyperplan qui maximise la marge entre les classes, tout en tolérant les erreurs pour améliorer les performances sur des ensembles de données complexes. Bien qu'efficaces pour traiter des données de grande dimension et résilientes aux points aberrants, les SVM présentent des défis liés à la sélection des paramètres et à l'interprétation des résultats dans le contexte multi-classes.




































