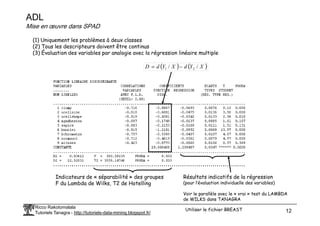
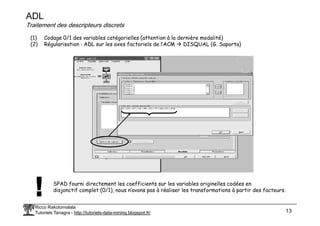
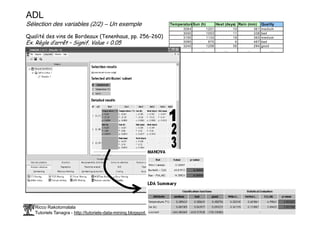
Le document traite de l'estimation des probabilités conditionnelles à l'aide du théorème de Bayes et des fonctions discriminantes linéaires en statistique. Il aborde également les avantages et inconvénients des méthodes, la sélection automatique des variables et des exemples pratiques d'application. Enfin, il mentionne des ouvrages de référence pour approfondir le sujet.



![(X1) pet_length vs. (X2) pet_w idth by (Y) type
2 3
µ
[1] Hypothèse de normalité
La normalité de la probabilité conditionnelle P(X/Y)
)'
(
)
(
)
det(
2
1
,
,
1
2
1
1
1
)
( k
k
k
k
k
J
J
X
X
y
v
X
v
X
e
P
µ
µ
π
−
Σ
−
−
Σ
=
=
−
=
K
Loi normale multidimensionnelle
Ricco Rakotomalala
Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 3
Iris-setosa Iris-versicolor Iris-virginica
6
5
4
3
2
1
2
1
1
µ
2
µ
3
µ
k
µ Centre de gravité conditionnelle
k
Σ Matrice de variance co-variance
conditionnelle](https://image.slidesharecdn.com/analysediscriminante-220526001024-f8927ab1/85/analyse_discriminante-pdf-3-320.jpg)
![[2] Homoscédasticité
Égalité des matrices de variance co-variance conditionnelles
K
k
k ,
,
1
, K
=
Σ
=
Σ
(X1) pet_length v s . (X2) pet_w idth by (Y ) ty pe
2
2
µ
3
µ
Ricco Rakotomalala
Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 4
Iris -s etos a Iris -v ers ic olor Iris -v irginic a
6
5
4
3
2
1
1
1
µ
2
µ](https://image.slidesharecdn.com/analysediscriminante-220526001024-f8927ab1/85/analyse_discriminante-pdf-4-320.jpg)
![Fonction linéaire discriminante
Simplification des formules sous [1] et [2]
)'
(
)
(
)
(
ln 1
2
1
k
k
y
X X
X
P k
µ
µ −
Σ
−
−
∝ −
Avec les estimations sur l’échantillon de taille n, K classes et J descripteurs
=
k
x 1
,
ˆ M
µ Moyennes conditionnelles
La probabilité conditionnelle est donc proportionnelle à
Ricco Rakotomalala
Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 5
=
J
k
k
x ,
ˆ M
µ Moyennes conditionnelles
∑
=
Σ
×
−
=
Σ
K
k
k
k
n
K
n 1
ˆ
1
ˆ Matrice de variance co-variance
intra-classes](https://image.slidesharecdn.com/analysediscriminante-220526001024-f8927ab1/85/analyse_discriminante-pdf-5-320.jpg)
![( )
[ ] '
2
1
'
ln
)
,
( 1
1
k
k
k
k
k X
y
Y
P
X
Y
d µ
µ
µ −
−
Σ
−
Σ
+
=
=
Fonction discriminante linéaire proportionnelle à P(Y=yk/X)
L
L J
J
X
a
X
a
X
a
a
X
Y
d
X
a
X
a
X
a
a
X
Y
d ,
1
2
2
,
1
1
1
,
1
0
,
1
1
)
,
(
)
,
(
+
+
+
+
=
+
+
+
+
=
Règle d’affectation
)
,
(
max
arg
* X
Y
d
y k
k =
Fonction linéaire discriminante
Linéarité du modèle d’affectation
Ricco Rakotomalala
Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 6
L
L J
J X
a
X
a
X
a
a
X
Y
d ,
2
2
2
,
2
1
1
,
2
0
,
2
2 )
,
( +
+
+
+
=
)
,
(
max
arg
* X
Y
d
y k
k
k =
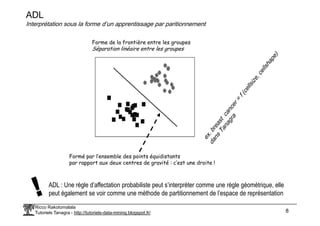
ADL propose les mêmes performances que les autres méthodes linéaires
>> Elle est assez robuste par rapport à l’hypothèse de normalité
>> Elle est gênée par la forte violation de l’homoscédasticité (formes de nuages très différentes)
>> Elle est sensible à une forte dimensionnalité et/ ou la corrélation des descripteurs (inversion de matrice)
>> Elle n’est pas opérationnelle si la distribution est multimodale (ex. 2 ou + « blocs » de nuages pour Y=Yk)
Avantages et inconvénients
Montrer exemple avec le fichier BINARY WAVES – Lecture des résultats et déploiement](https://image.slidesharecdn.com/analysediscriminante-220526001024-f8927ab1/85/analyse_discriminante-pdf-6-320.jpg)



![ADL
Cas particulier du problème à 2 classes (K = 2)
La variable à prédire prend deux modalités :: Y={+,-}
J
J
J
J
J
J
X
c
X
c
X
c
c
X
d
X
a
X
a
X
a
a
X
d
X
a
X
a
X
a
a
X
d
+
+
+
+
=
+
+
+
+
=
−
+
+
+
+
=
+
−
−
−
−
−
+
+
+
+
K
L
L
2
2
1
1
,
2
2
,
1
1
,
0
,
,
2
2
,
1
1
,
0
,
)
(
)
,
(
)
,
(
Règle d’affectation
D(X) > 0 Y = +
>> D(X) est communément appelé un score, c’est la propension à être positif.
>> Le signe des coefficients « c » donne une idée sur le sens de la causalité.
Interprétation
Ricco Rakotomalala
Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 11
>> Le signe des coefficients « c » donne une idée sur le sens de la causalité.
>> Lorsque les Xj sont elles-mêmes des variables indicatrices (0/1), les coefficients « c »
peuvent être lus comme des « points » attribués aux individus portant le caractère Xj
On peut voir une analogie forte entre la LDA et la régression linéaire multiple dans laquelle
la variable endogène Y est codée 1/0 [ 1 = + ; 0 = - ].
Nous pouvons nous inspirer des résultats de la régression pour évaluer globalement le
modèle et surtout pour évaluer individuellement la « significativité » des coefficients « c »
test de Student (attention, la transposition du test n’est pas totale)
Évaluation](https://image.slidesharecdn.com/analysediscriminante-220526001024-f8927ab1/85/analyse_discriminante-pdf-11-320.jpg)