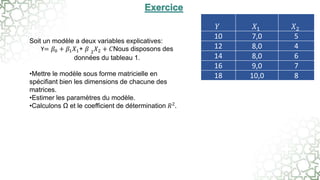
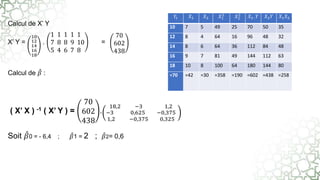
Ce document traite de la régression linéaire multiple, une méthode d'analyse statistique qui explore la relation entre une variable dépendante et plusieurs variables indépendantes. Il décrit comment estimer les paramètres du modèle à l'aide de la méthode des moindres carrés et introduit des concepts tels que les résidus, la variabilité totale et le coefficient de détermination pour évaluer la qualité de l'ajustement du modèle. Le texte aborde également des aspects techniques liés à la manipulation des données et à l'interprétation des résultats.