Téléchargé 66 fois




![(
𝑌1
⋮
𝑌𝑖
⋮
𝑌𝑛)
=
[
1
⋮
1
𝑥11
⋮
𝑥𝑖1
𝑥12
⋮
𝑥𝑖2
⋮ ⋮ ⋮
1 𝑥 𝑛1 𝑥 𝑛2
⋯
⋱
⋯
𝑥1𝑝
⋮
𝑥𝑖𝑝
⋮
𝑥 𝑛𝑝] (
𝛽0
𝛽1
𝛽2
⋮
𝛽 𝑝)
+ (
𝜀1
⋮
𝜀𝑖
⋮
𝜀 𝑛
)
𝑌 = 𝑋 𝛽 + 𝜀
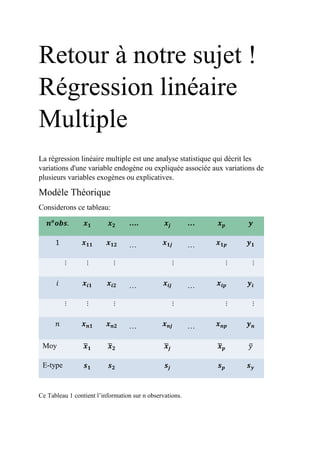
Il est facile de voir que 𝑌 est le vecteur des variables explicatives, X matrice à n lignes et
p+1 colonnes des variables prédictrices, 𝛽 vecteur des paramètres inconnus et 𝜀 celui des
termes d’erreurs.
Les hypothèses
Dans le modèle linéaire multiple , les hypothèses d'exogénéité, de non colinéarité, de non
corrélation des termes d'erreur et d'homoscédasticité doivent être respectées.
Exogeneité : Les variables explicatives ne sont pas corréler au terme d’erreur c’est-a-dire
𝑐𝑜𝑣𝑎𝑟(𝜀𝑗, 𝑥𝑖𝑘) = 0 , ∀𝑖, 𝑗, 𝑘. Avec 𝑋 constant, on a𝐸(𝜀) = 0⃗ .
Homoscédasticité : ∀𝜀𝑗 ,𝑗=1,…,𝑛, 𝑣𝑎𝑟(𝜀𝑗) = 𝜎2
, 𝑎𝑣𝑒𝑐 𝜎 𝑐𝑜𝑛𝑠𝑡𝑎𝑛𝑡.
Non colinearité des termes d’erreur : ∀𝑖, 𝑗, 𝑗 ≠ 𝑖, 𝑐𝑜𝑣𝑎𝑟(𝜀𝑖, 𝜀𝑗) = 0.
On peut aussi dire que les termes d’erreur doivent suivre une loi normale
centrée réduites.
Un vecteur comme variable aléatoire????????
Il n’est pas nouveau d’entendre parler de vecteur aléatoire en statistique ou
probabilité. Ce qui nous intéresse maintenant est de savoir l'espérance et la
variance d’un vecteur aléatoire.
L’espérance d’un vecteur aléatoire est le vecteur des espérances. Par exemple :
𝐸(𝜀) =
(
𝐸( 𝜀1)
⋮
𝐸( 𝜀𝑗)
⋮
𝐸( 𝜀 𝑛))](https://image.slidesharecdn.com/709f41e1-1f1b-49f5-8fd1-3667b5c7e556-160317172816/85/Regression-lineaire-Multiple-Autosaved-Autosaved-6-320.jpg)


![Donc : 𝐶𝐶′
= (𝑋′
𝑋)−1
𝑋′
𝑋(𝑋′
𝑋)−1
=> 𝐶𝐶′
= (𝑋′
𝑋)−1
.
De ce resultat, on obtient : 𝑽(𝜷̂) = 𝝈 𝟐(𝑿′
𝑿)−𝟏
.
Nous servirons par la suite avec ce résultat pour trouver des intervalles de confiance des paramètres
estimés.
Si on se sert du point moyen, le modèle est parfaitement ajusté c’est-à-dire 𝑦𝑖̅ = 𝛽0
̂ + 𝛽1
̂ 𝑥̅𝑖1 + 𝛽2
̂ 𝑥̅𝑖2 +
⋯ 𝛽 𝑝
̂ 𝑥̅𝑖𝑝.
Estimation de la variance des résidus 𝝈 𝟐
Definissons 𝑆𝐶𝐸 𝑅 comme etant la Somme des Carrés des Ecarts due aux Résidus.
𝑆𝐶𝐸 𝑅 = ∑ 𝑒𝑖
2
𝑖 .
𝜎2
peut être estimée par ∑
(𝑦 𝑖−𝑦̂ 𝑖)2
𝑛−𝑝−1
=𝑖
𝑆𝐶𝐸 𝑅
𝑛−𝑝−1
. Cet estimateur est non biaisé. En effet,
Il est évident que
𝑆𝐶𝐸 𝑅
𝜎2 ~𝜒 𝑛−(𝑝+1)
2
,et que 𝐸 (
𝑆𝐶𝐸 𝑅
𝜎2 ) = 𝑛 − 𝑝 − 1. On a alors : 𝐸 (
𝑆𝐶𝐸 𝑅
𝑛−𝑝−1
) = 𝜎2
. On
tombe en moyenne sur la vraie valeur de 𝜎2
alors on peut conclure que notre estimateur n’est pas
biaisés.
Quelques proprietes des residus
1) 𝑆𝐶𝐸 𝑅 = ∑ 𝑒𝑖
2
𝑖 <=> 𝑆𝐶𝐸 𝑅 = 𝐸′
𝐸. 𝑎𝑣𝑒𝑐 𝐸 = 𝑌 − 𝑋𝛽̂ , 𝑜𝑛 𝑎 ∶ 𝐸′ = 𝑌′ − 𝛽̂′𝑋′ . Ces
relations impliquent 𝑆𝐶𝐸 𝑅 = (𝑌′
− 𝛽̂′
𝑋′
)(𝑌 − 𝑋𝛽̂) => 𝑆𝐶𝐸 𝑅 = 𝑌′
𝑌 − 𝑌′
𝑋𝛽̂ −
𝛽̂′
𝑋′
𝑌 + 𝛽̂′
𝑋′
𝑋𝛽̂
𝑜𝑟 𝑋′
𝑋𝛽̂ = 𝑋′𝑌 alors 𝛽̂′
𝑋′
𝑋𝛽̂ = 𝛽̂′
𝑋′
𝑌 , 𝑺𝑪𝑬 𝑹 = 𝒀′
𝒀 − 𝒀′
𝑿𝜷̂ .
2) Calcule de 𝑋′
𝐸. 𝑋′
𝐸 = 𝑋′
( 𝑌 − 𝑋𝛽̂) <=> 𝑋′
𝐸 = 𝑋′ 𝑌 − 𝑋′
𝑋𝛽̂ . Avec 𝑋′
𝑋𝛽̂ = 𝑋′𝑌 , on
trouve que : 𝑋′
𝐸 = 𝑋′ 𝑌 − 𝑋′
𝑌. Au final : 𝑿′
𝑬 = 𝟎⃗⃗ .
Ceci veut dire que
[
1
𝑥11
𝑥12
⋮
𝑥1𝑝
1
𝑥21
𝑥22
⋮
𝑥1𝑝
⋯
…
⋯
…
1
𝑥 𝑛1
𝑥 𝑛2
⋮
𝑥 𝑛𝑝]
× [
𝑒1
𝑒2
⋮
𝑒 𝑛
] =
[
0
0
0
⋮
0]
C’est equivalent à dire : {
∑ 𝑒𝑖𝑖 = 0
∑ 𝒙𝒊𝒋 𝒆𝒊
𝒏
𝒊=𝟏 = 𝟎, ∀𝒋 = 𝟏 … 𝒑.
Décomposition de la variabilité
SCER : Somme des Carrées des Ecarts due aux résidus ∑ 𝑒𝑖
2
𝑖 avec 𝑒𝑖 = 𝑦𝑖 − 𝑦̂𝑖 .
SCEM : Somme des Carrées des Ecarts due au Modèle . ∑ (𝑦̂𝑖 − 𝑦̅)2
𝑖
SCET : Somme des Carrées des Ecarts Totale . ∑ (𝑦𝑖 − 𝑦̅)2
𝑖
Propriété](https://image.slidesharecdn.com/709f41e1-1f1b-49f5-8fd1-3667b5c7e556-160317172816/85/Regression-lineaire-Multiple-Autosaved-Autosaved-9-320.jpg)






Le document traite de la régression linéaire multiple, une méthode statistique qui examine les variations d'une variable dépendante en fonction de plusieurs variables indépendantes. Il explique le modèle théorique, les hypothèses à respecter, et détaille la méthode des moindres carrés pour estimer les paramètres du modèle. Enfin, il aborde l'estimation de la variance des résidus et le testing des modèles statistiques.



























































