Téléchargé 128 fois








![Traitement graphe: CYPHER
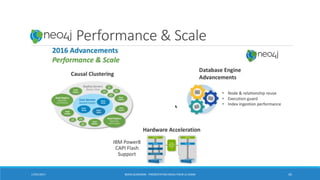
LATENCE DES REPONSES DES REQUETES
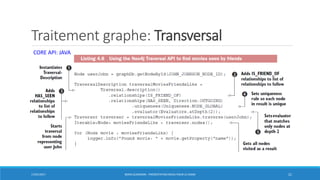
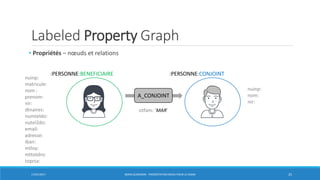
• Avec une base de données graphe, la plupart des requêtes suivent un schéma dans lequel un
index est utilisé simplement pour trouver le(s) nœud(s) de départ.
• Le reste du parcours utilise ensuite une combinaison de chasse au pointeur + pattern
matching pour rechercher les données. Requête CYPHER:
MATCH (:BAILLEUR)-[r1:EST_BAILLEUR_DE]->(b)-[r2:A_CONJOINT]->(:CONJOINT)
• La performance ne dépend pas de la taille totale de l'ensemble de données, mais uniquement
sur les données interrogées (sous-graphes).
• Cela conduit à des temps de performance qui sont à peu près constant (liés à la taille de
l'ensemble de résultat), même si la taille de l'ensemble de données augmente.
17/01/2017 BORIS GUARISMA - PRÉSENTATION NEO4J POUR LE CNAM 20
“openCypher project aims to bring graph querying to the masses, with support from Oracle,
Databricks, Tableau and other leading companies”](https://image.slidesharecdn.com/prsentationbdgraphes-20170117public-170123123525/85/Base-de-donnees-graphe-et-Neo4j-20-320.jpg)














![Références
• [1] Robinson I., Webber J, Eifrem E., “Graph Databases”, O’Reilly, 2nd edition, ISBN
9781491930892
• [2] Vukotic A., Watt N., “Neo4j in Action”, Manning Publications, ISBN 9781617290763
• [3] Wikipedia, “Base de données orientée graphe”,
https://fr.wikipedia.org/wiki/Base_de_donn%C3%A9es_orient%C3%A9e_graphe
• [4] Willemsen C., “Découverte de Neo4j, la base de données graphe”,
http://neoxygen.io/articles/decouverte-de-neo4j.html , version 1.1, 14-01-2015
• [5] Maury F., “Pourquoi s’intéresser aux graph-databases ?”,
http://www.arolla.fr/blog/2013/10/pourquoi-sinteresser-aux-graph-databases/
• [6] Fauvet C., “Nouvelles opportunités pour les données fortement connectées: La base de
graphe Neo4j”, 10 décembre 2013
• [7] Robert M., Dutheil L., Domenjoud M., « Introduction aux graphes avec Neo4j et Gephi »
http://blog.octo.com/introduction-aux-graphes-avec-neo4j-et-gephi/
• [8] Lyon William, Introduction to Graph Databases and Neo4j - January 14, 2016,
https://www.youtube.com/watch?v=83P81ebgCxA
17/01/2017 BORIS GUARISMA - PRÉSENTATION NEO4J POUR LE CNAM 49](https://image.slidesharecdn.com/prsentationbdgraphes-20170117public-170123123525/85/Base-de-donnees-graphe-et-Neo4j-49-320.jpg)


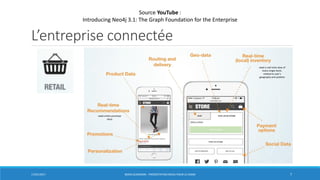
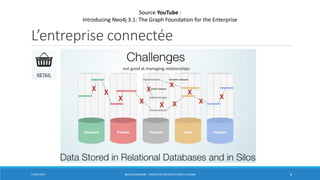
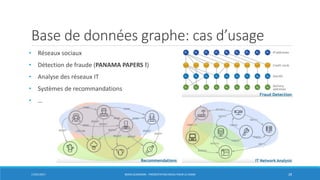
La présentation aborde Neo4j, une base de données graphe, et ses avantages par rapport aux systèmes de gestion de base de données relationnelles, notamment pour la gestion des données fortement connectées. Elle couvre des sujets tels que l'architecture, le stockage et le traitement des graphes, ainsi que des cas d'usage pratiques comme l'analyse des réseaux sociaux et la détection de fraude. Neo4j offre une puissance dans les requêtes graphiques grâce à son langage Cypher et permet une grande scalabilité et performance dans les traversals.






































![[FRENCH] - Neo4j and Cypher - Remi Delhaye](https://cdn.slidesharecdn.com/ss_thumbnails/presentation-140424120458-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




























