



![Relation linéaire
• Soit les observations enregistrées dans le
tableau.
• nombre lamantins décédés
• nombre de bateaux enregistrés
• Le graphique montre une relation
croissante et presque linéaire:
• le nombre de lamantins décédés augmente
quand le nombre de bateaux enregistrés
augmente
6/30/2016 BORIS GUARISMA - FORMATION DATA SCIENTIST - PARTIE 5 - RÉGRESSION LINÉAIRE 4
Nombre de lamantins décédés par des bateaux à moteur (en
milliers) le long des côtes de la Floride, entre 1981 et 1990
source [2] Bibliographie](https://image.slidesharecdn.com/0502reglineairev1draft-160630085556/85/5-2-Regression-lineaire-4-320.jpg)




![Relation linéaire
• Version « machine learning »
• notation β = Ɵ
• m observations x n variables
• X[., 1] = 𝒙 𝟎
(𝒊)
= 1 variable dummy
• መ𝑓=> fonction hypothèse h(X) = ƟT X
• Fonction de coût à minimiser
avec l’algorithme du gradient
6/30/2016 BORIS GUARISMA - FORMATION DATA SCIENTIST - PARTIE 5 - RÉGRESSION LINÉAIRE 9
n+1 colonnes
cas d’une régression linéaire simple
𝜖 ℝ
versions
vectorisées
source [3] Bibliographie](https://image.slidesharecdn.com/0502reglineairev1draft-160630085556/85/5-2-Regression-lineaire-9-320.jpg)

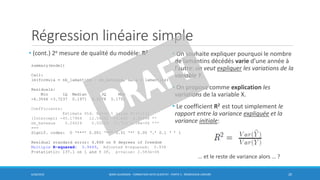
![Régression linéaire simple
• Simple = une seule variable X
• On ajuste la droite avec une fonction de coût
quadratique
• On aurait pu utiliser une fonction de coût en
valeur absolue, plus robuste
• voir ligne noire (pas pointillée!) sur le figure
• Malgré cela, le coût quadratique est le coût le
plus souvent utilisé
6/30/2016 BORIS GUARISMA - FORMATION DATA SCIENTIST - PARTIE 5 - RÉGRESSION LINÉAIRE 11
source [5] Bibliographie](https://image.slidesharecdn.com/0502reglineairev1draft-160630085556/85/5-2-Regression-lineaire-11-320.jpg)
![Régression linéaire simple
• Point aberrants (outliers)
• Ne pas les éliminer systématiquement, il faut
s’assurer si mauvaise imputation, etc. et le placer
correctement dans le contexte de l’étude
• Alternative: utiliser une méthode plus robuste …
6/30/2016 BORIS GUARISMA - FORMATION DATA SCIENTIST - PARTIE 5 - RÉGRESSION LINÉAIRE 12
n’affecte pas la direction
de la droite ajustée
affecte la direction de
la droite ajustée
rlm() du package MASS
source [4] Bibliographie
source [4] Bibliographie
Coursera, Data Analysis and Statistical Inference MOOC, Duke University](https://image.slidesharecdn.com/0502reglineairev1draft-160630085556/85/5-2-Regression-lineaire-12-320.jpg)





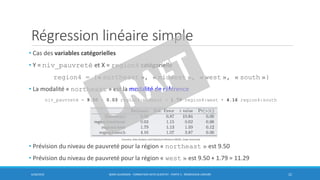
![Régression linéaire simple
• Intervalle de confiance à 95% de መ𝛽1
6/30/2016 BORIS GUARISMA - FORMATION DATA SCIENTIST - PARTIE 5 - RÉGRESSION LINÉAIRE 18
summary(model)
Call:
lm(formula = nb_lamantins ~ nb_bateaux, data = lamantins)
Residuals:
Min 1Q Median 3Q Max
-6.3566 -3.7237 0.1971 4.2178 5.1751
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -45.17964 12.54392 -3.602 0.00696 **
nb_bateaux 0.24024 0.02052 11.710 2.58e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.868 on 8 degrees of freedom
Multiple R-squared: 0.9449, Adjusted R-squared: 0.938
F-statistic: 137.1 on 1 and 8 DF, p-value: 2.583e-06
• degrés de liberté: df = n – 2 = 8
• t*8 = 2.03
• CI95 = 𝛽1 ± t*8 x SE( 𝛽1)
= Estimate ± 2.03 x Std. Error
= 0.24024 ± 2.03 x 0.02052
= (0.19 , 0.28)
On est à 95% sûr que la vraie valeur de β1 se
trouve dans l’intervalle [0.19 , 0.28]
qt(p = 0.025, df = 8)
[1] -2.306004
source [4] Bibliographie](https://image.slidesharecdn.com/0502reglineairev1draft-160630085556/85/5-2-Regression-lineaire-18-320.jpg)




![Régression linéaire multiple
• Exercice « The Marketing Plan »
• fichier advertising_data.txt (200 x 4)
• source [1], voir Bibliographie
1. Y a-t-il une relation entre le budget de publicité et les
ventes ?
2. Quelle est la "force" de cette relation ?
3. Quel média contribue aux ventes ?
4. Dans quelle mesure chaque média contribue-t-il aux
ventes?
5. Comment prédire les futures ventes avec le plus
d'exactitude possible ?
6. La relation est-elle linéaire ?
7. Y a-t-il une synergie entre les média ?
6/30/2016 BORIS GUARISMA - FORMATION DATA SCIENTIST - PARTIE 5 - RÉGRESSION LINÉAIRE 25
réponse
James and al., An introduction to Statistical Learning, ISBN 9781461471370, Springer, 2014](https://image.slidesharecdn.com/0502reglineairev1draft-160630085556/85/5-2-Regression-lineaire-25-320.jpg)











Ce document présente les concepts fondamentaux de la régression linéaire, y compris les relations entre les variables, la fonction de coût, et les méthodes de minimisation. Il inclut des exemples pratiques sur la régression linéaire simple et multiple, ainsi que sur l'interprétation des résultats dans le langage R. Les mesures de qualité telles que l'erreur quadratique moyenne (RMSE) et le coefficient de détermination (R²) sont également abordées.


































































