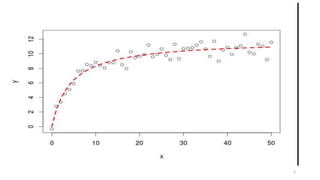
Le document traite de la régression non linéaire, soulignant la nécessité d'utiliser des modèles non linéaires lorsque l'effet d'une variable dépend de ses niveaux. Il présente des exemples de modèles quadratiques et polynomiaux, ainsi que des modèles logarithmiques, et discute des tests d'hypothèses pour évaluer la pertinence des modèles. Enfin, il indique que le choix du modèle dépend des spécificités des données et du contexte de l'analyse.



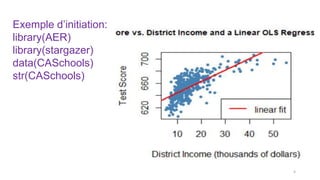
















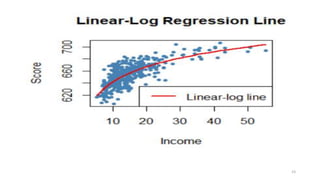
![# Graphique de la relation:
plot(score ~ income, col = "steelblue",pch = 20, data =
CASchools,ylab="Score",xlab="Income", main = "Linear-Log
Regression Line")
order_id <- order(CASchools$income)
lines(CASchools$income[order_id],
fitted(LinearLog_model)[order_id], col = "red",
lwd = 2)
legend("bottomright",legend = "Linear-log line",lwd = 2,col
="red")
22](https://image.slidesharecdn.com/modelenonlineaire-240527165916-357a8fa7/85/modele-non-lineaire-machine-learning-and-data-science-22-320.jpg)



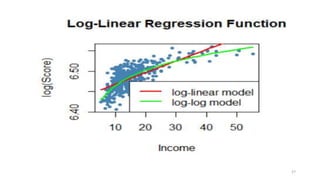


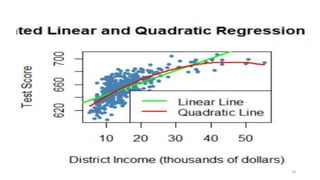
![# Ajoutons the linear-log regression line
order_id <- order(CASchools$income)
lines(CASchools$income[order_id],
fitted(LinearLog_model)[order_id],
col = "darkgreen",
lwd = 2)
30](https://image.slidesharecdn.com/modelenonlineaire-240527165916-357a8fa7/85/modele-non-lineaire-machine-learning-and-data-science-30-320.jpg)
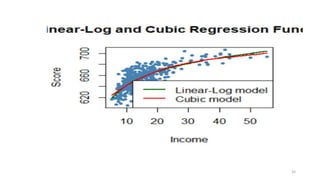
![# Ajoutons cubic model:
#
lines(x = CASchools$income[order_id],
y = fitted(cubic_model)[order_id],
col = "red",
lwd = 2)
# add a legend
legend("bottomright",
legend = c("Linear-Log model", "Cubic model"),
lwd = 2,
col = c("darkgreen", "red"))
31](https://image.slidesharecdn.com/modelenonlineaire-240527165916-357a8fa7/85/modele-non-lineaire-machine-learning-and-data-science-31-320.jpg)