Téléchargé 165 fois


















![Map-ReduceTechnique de traitement des données de grandes taillesActeurs réputés:GoogleHadoopCouchDBMongoDBMapInputSortReduce(C1V1)(K2V2)(K2[V2 V2’])(K3V3)Traitement localTraitement global](https://image.slidesharecdn.com/nosql-110719114112-phpapp02/85/noSQL-38-320.jpg)



![Bases de documents{ "_id" : ObjectId("4c220a42f3924d31102bd866"), "cli_id" : ObjectId("4c220a42f3924d31102bd867"), "date" : "2011-07-19", "montant_total” : 123, "tva” : 20.16, "articles” : [ { “art_id” : ObjectId("4c220a42f3924d31102bd85b"), “qte” : 2, "pu” : 50 }, { “art_id” : ObjectId("4c220a42f3924d31102bd869"), "qte” : 1, "pu": 23 } ]}Collection de documents JSON](https://image.slidesharecdn.com/nosql-110719114112-phpapp02/85/noSQL-44-320.jpg)



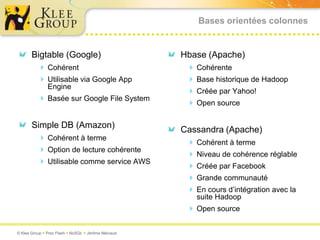
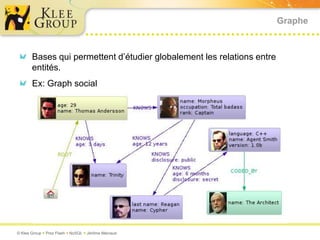


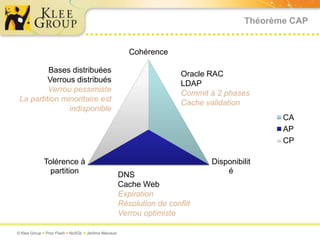
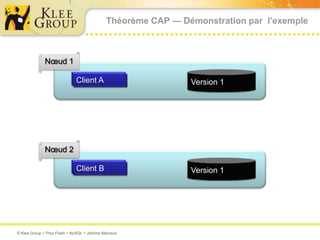
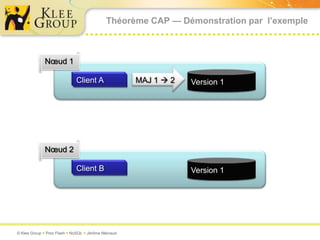
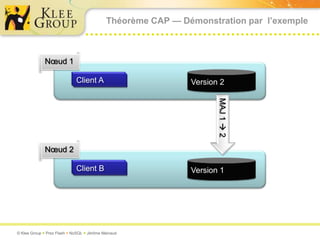
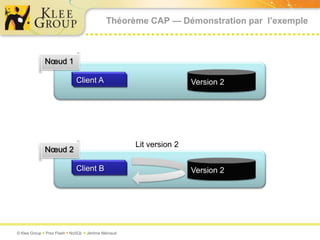
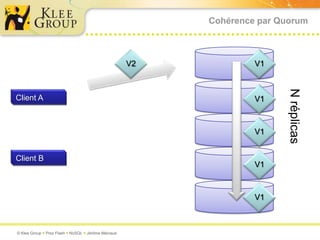
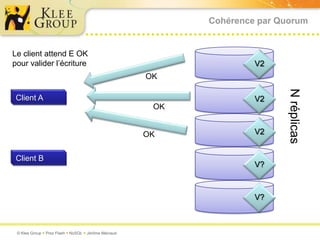
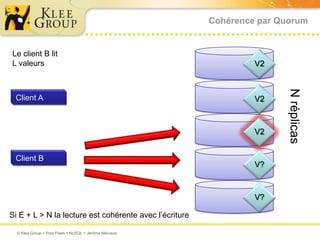
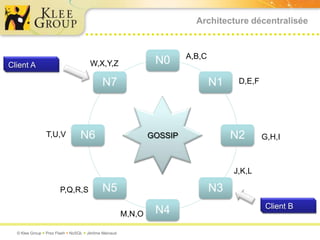
Le document traite des bases de données NoSQL et de leurs alternatives aux systèmes relationnels traditionnels SQL. Il met en lumière des concepts fondamentaux comme le théorème CAP, les performances, et les architectures décentralisées, ainsi que des exemples de différentes types de bases NoSQL comme les bases de documents et orientées colonnes. Enfin, il présente des techniques de traitement de données telles que MapReduce et discute des défis liés à la cohérence et à la montée en charge des systèmes de données modernes.

























































