Téléchargé 27 fois





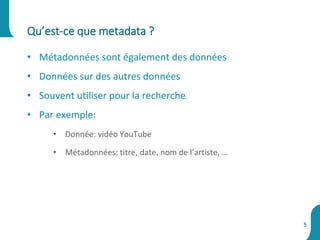


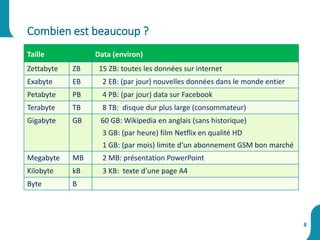
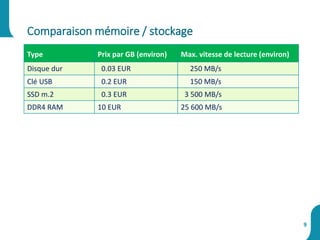
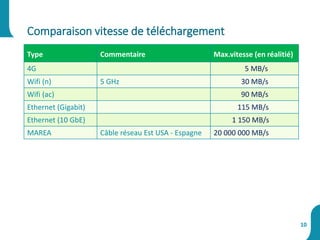






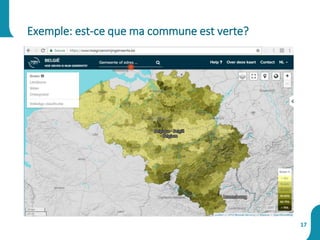


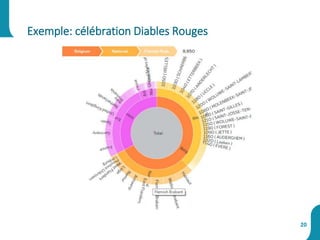











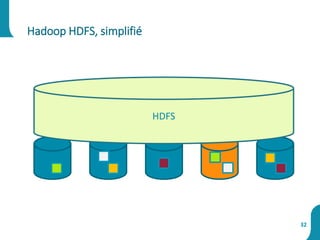





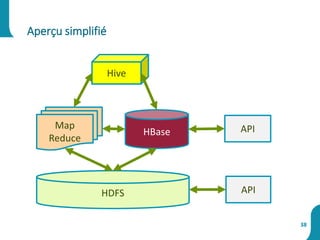









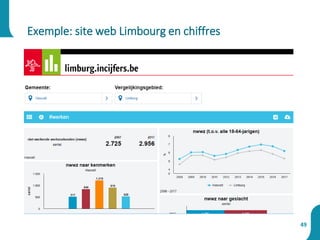





Le document présente une synthèse sur le big data et l'open data, en définissant des concepts tels que la gestion, la collecte et la sécurité des données. Il souligne l'importance croissante de ces données dans divers secteurs, allant de la science à l'industrie, et examine les implications économiques et sociétales associées. Enfin, le document décrit des plateformes et outils associés à l'analyse et à la visualisation des données.



























































