Téléchargé 46 fois



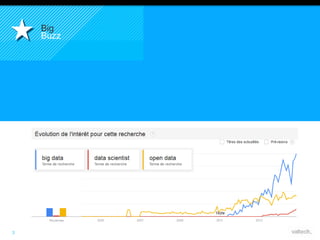






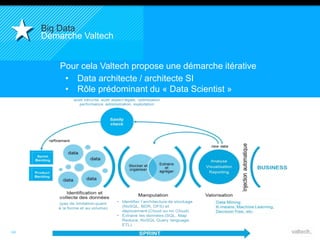

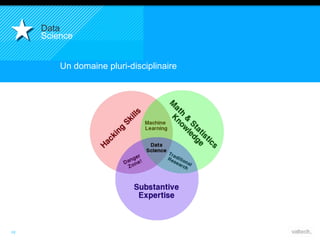
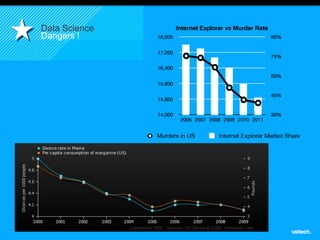




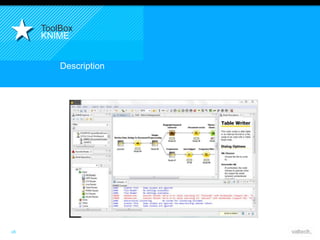
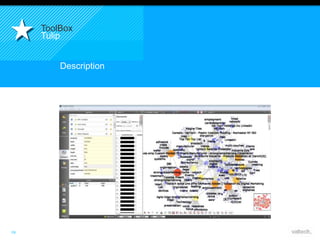

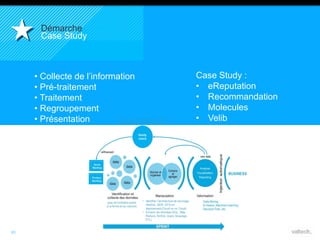


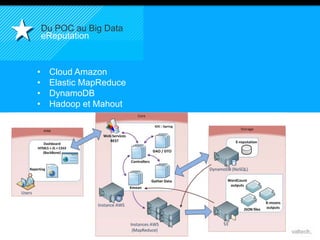
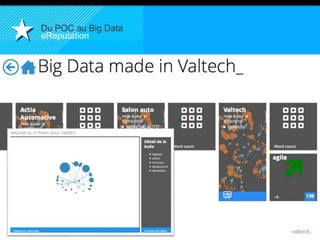

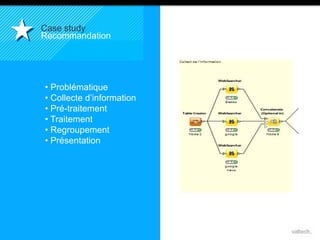

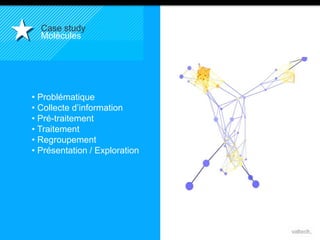

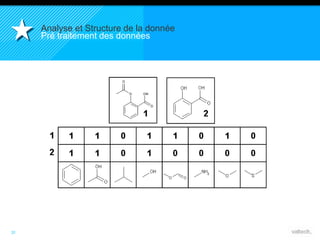
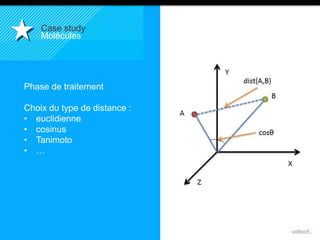
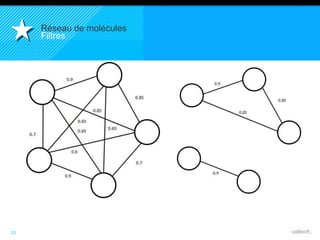
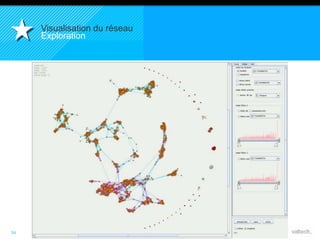

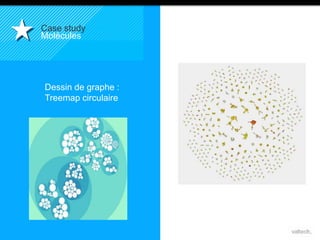
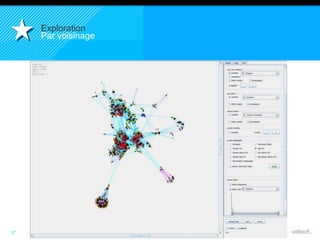


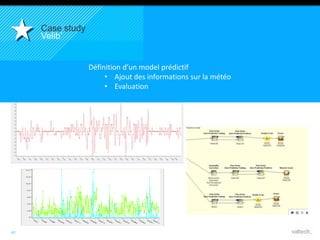




Le document présente le concept d'Open Data Scientist, en expliquant ses différentes applications à travers plusieurs études de cas telles que l'e-réputation, la recommandation, les molécules et le service Velib. Il aborde également les défis et les outils du Big Data, ainsi que la méthodologie adoptée par Valtech pour intégrer ces technologies de manière itérative. Enfin, il souligne l'importance de l'open data comme source d'innovation et de réutilisation des données.












































![C:\Fakepath\Offsho[1]](https://cdn.slidesharecdn.com/ss_thumbnails/cfakepathoffsho1-100223205532-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[Veille thématique et décryptage] Cannes Lions 2014](https://cdn.slidesharecdn.com/ss_thumbnails/valtech-canneslions2014-140702122046-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ Revue Innovations ] Valtech - Mobile World Congress](https://cdn.slidesharecdn.com/ss_thumbnails/valtech-mwc14-140310065604-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ Veille de tendances ] Valtech : Objets connectés](https://cdn.slidesharecdn.com/ss_thumbnails/valtech-ces2014-140121054330-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



