Téléchargé 38 fois














![Cas pratique
«parmi nos utilisateurs enregistrés, quels sont ceux qui utilisent le formulaire de recherche
depuis la page d’accueil ?»
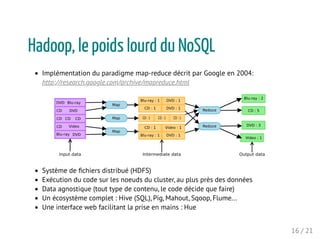
Import des logs en continu via Flume
Application mapreduce
1. [MAP] extraction des lignes de log du serveur web
2. [MAP] construction d'une clé pour chaque ligne: user id + timestamp
3. [MAP] valeur extraite pour chaque ligne : l'URL
4. [REDUCE] regroupement de toutes les lignes d'un utilisateur sur 1 reducer, tri
sur chaque reducer par user id
5. [REDUCE] tri secondaire par timestamp
6. [REDUCE] le code regarde deux lignes consécutives: la succession des 2 pages
attendues produit un 1, toute autre séquence un 0
7. [REDUCE] on compte les "1" par user id
Résultats écrits sur HDFS ou exportés vers une BDD via Sqoop
18 / 21](https://image.slidesharecdn.com/croisieresurledatalake-davidmorel-151207084843-lva1-app6891/85/Croisiere-sur-le-data-lake-18-320.jpg)




Le document traite des grandes tendances et défis liés à l'ère du big data, soulignant l'importance de la compréhension et de l'analyse des données plutôt que leur simple collecte. Il aborde les rôles de la science des données, du machine learning, ainsi que des systèmes de gestion de bases de données NoSQL et de Hadoop, tout en mentionnant les enjeux de qualité des données. Enfin, il met en lumière l'évolution du paysage technologique et l'importance de la visualisation des données dans le processus d'analyse.










![[French] Matinale du Big Data Talend](https://cdn.slidesharecdn.com/ss_thumbnails/matinaledubigdatatalend-141008041011-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























































